

Hey everyone! If you have been reading my pieces for a while, you know I like to write on technical topics, share real-time experiences, and cover emerging developments in the AI space. As someone working in AI, I constantly field LLM related questions from colleagues and friends. Right from the beginning, one question has come up so often that I knew it deserved its own dedicated post.
The question? "How to choose the right LLM?"
And I’m not the only one facing this question. The Cursor team has encountered it too.

Here’s what they shared. the Cursor team put together a model guide showing which model works best for each task.
So, in this post, we are going to see "how to choose the right LLM" in detail.
But before we address the above question, we need to ask another question,
"What is the use-case?", Answer this, and we are already halfway to picking the right model.
Meanwhile, feel free to check some of my other AI articles you might find interesting.
With that said,
Before we learn how to choose the right LLM, let us quickly get familiar with the Major Model providers in the AI field. The market is split between two main categories, proprietary and open-source models.
On the proprietary side, we have got three Major Players,
OpenAI's family: The GPT series (GPT-4o, GPT-4.1, GPT-4.1-mini) and the reasoning-focused o-series (o1-pro, o3, o4-mini, o4-mini-high). Check the full list of OpenAI models.
Anthropic's offerings: Claude 3.7 Sonnet, Claude 3.5 Sonnet, Claude 3.5 Haiku, and the recent Claude Sonnet 4, Claude Opus 4. Check out the complete list of Anthropic’s models.
Google's releases: Gemini Pro, Gemini Flash, Gemini 2.0 and the latest Gemini Diffusion. Get to know Google’s complete model list.
From the open-source side, we have key players like,
Meta's Llama series, Check the model library from Meta including all models.
Other players like Mistral, DeepSeek, and Qwen, are also available.
With so many options available, the real challenge is not about knowing which models exist. It is figuring out which one fits our specific needs. That is where these questions come in.
What does the model need to do? Answer questions? Generate code? Deal with documents.?
What type of data will the model handle? only text? or documents and images too?
What is typical input size? Short messages? Long documents? or extensive content?
What is the key trade-off? Speed? Accuracy? or Cost?
How much control is required? ready-to-use model or fully customized model?
What are the data privacy requirements? API-based model or cloud hosted or self-hosted?
Now, let us learn how to choose the right LLM by diving into each of these questions.
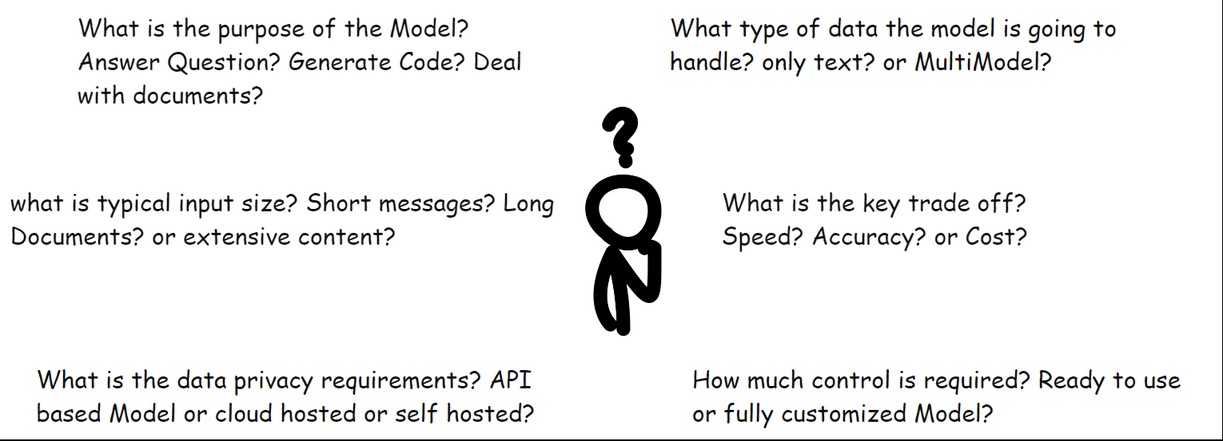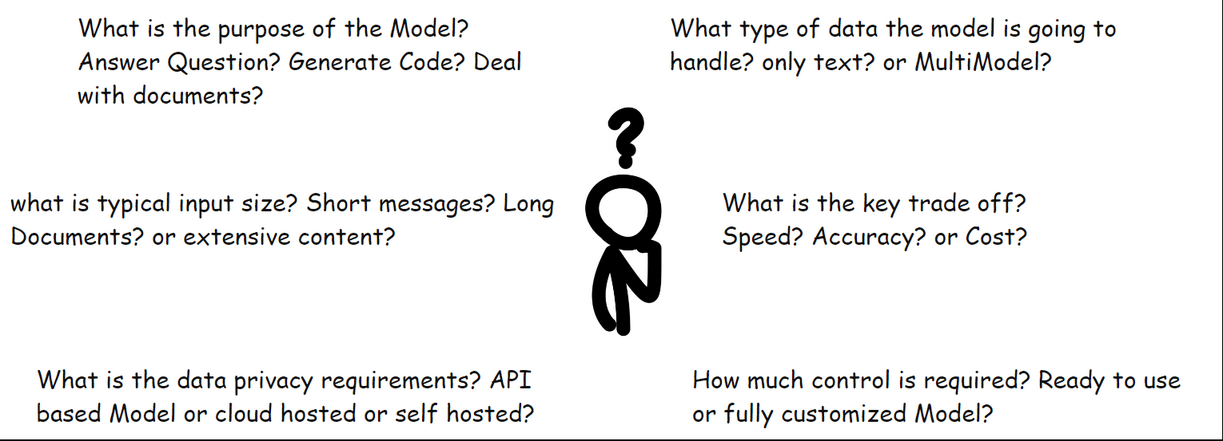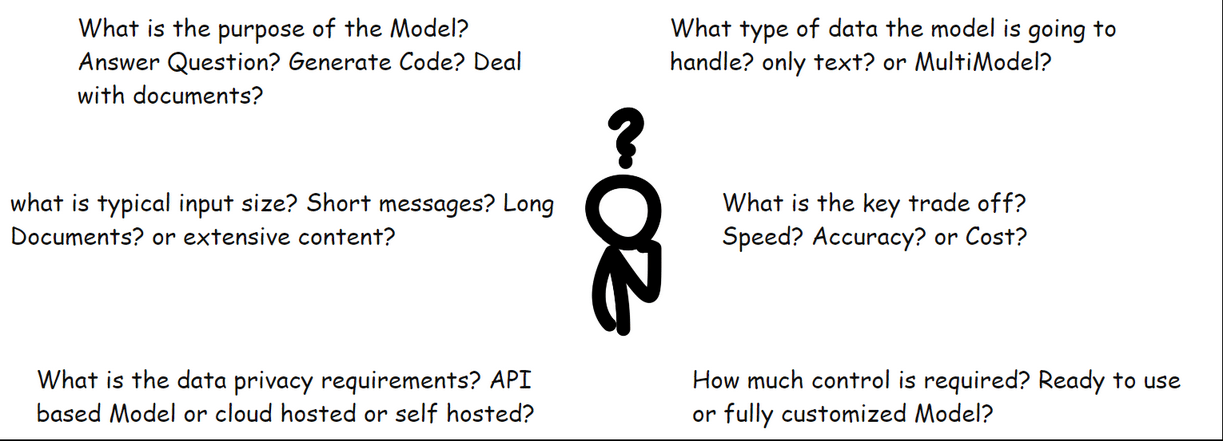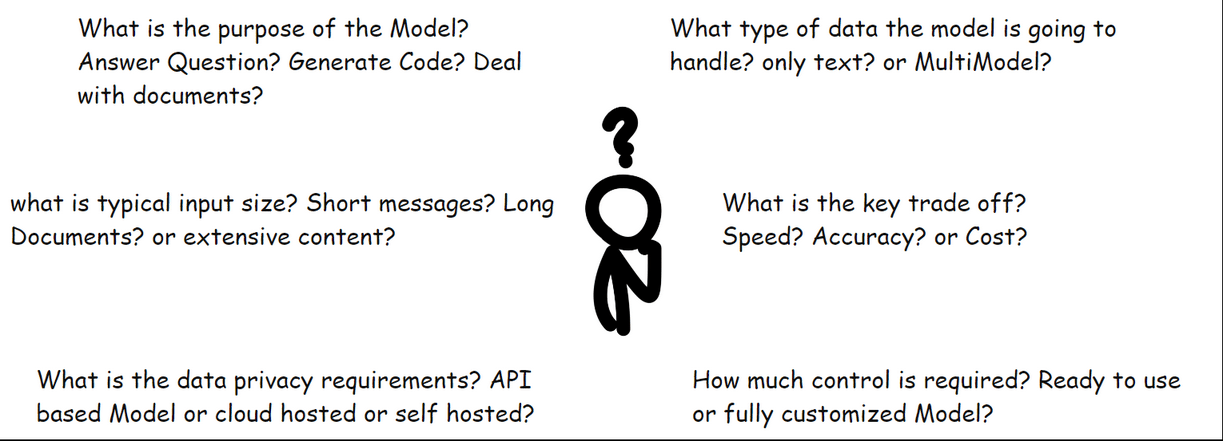
These questions might seem broad at first glance, but they are designed to work together. By the time we have answered all, we will have naturally filtered through the noise and landed on the perfect model for our specific needs.
1. Identify Model Purpose
This is where it all begins. Whenever we have a use case, we need to clearly understand what purpose the model should serve.
Simple examples are,
If building a chatbot is the use-case, then question-answering and conversation is the purpose of the model.
If automating code reviews is the use-case, then code analysis and bug detection is the purpose of the model.
If transcribing podcast episodes is the use-case, then speech-to-text conversion is the purpose of the model.
If processing legal documents is the use-case, then document analysis and information extraction is the purpose of the model.
So, it is important to identify the model's purpose from the use-case.
Once we identify our model's purpose, let us look at the diagram below. The specific purpose will fall into one of four main categories, Content/Reasoning, Coding, Document Parsing, or Audio/Video.
Most common use cases are listed here, but this is not an exhaustive list. If the specific use case isn't mentioned, don't worry, it likely falls under one of these four main categories. The point is not to find the exact match, but to figure out which bucket we are playing in.
Why does this matter? Because different models excel at different categories. Knowing where the use case fits help us skip the other categories that are not related to our workflow.

Now, here's where it gets interesting. Within each category, different models are built for specific purposes. And guess what? That's perfectly fine. We don't need one model to handle all different purposes in our use-case. We can use GPT-4.1 for content creation, o3 for complex reasoning tasks, and Claude for document summarization. The category gives us the direction, but the specific model choice depends on our exact purpose.
Now let us figure out which models work best for what purpose. I won't be giving a specific model for every single use case, that would be both impossible and outdated by next week.
Instead, I will share what I have learned from testing models across different providers like OpenAI, Anthropic, and others. Think of it as collective wisdom rather than rigid rules.
For coding tasks, Anthropic's Claude Sonnet models consistently shine. Whether it's code generation, debugging, or review, Claude just gets it right more often. When we need deep reasoning and analysis, where the model needs to think through multiple layers, that's where the o-series models (o3, o4-mini) really prove their worth. These are built specifically for complex reasoning.
For document parsing and OCR, we have got two paths. If we need to extract and understand content, multimodal LLMs like GPT-4o, Claude, or Gemini Pro works best. But if we just need clean text extraction at scale, specialized tools like Google Vision API or Azure Computer Vision beat them on pure OCR tasks.
And if we want to avoid vendor lock-in or need more control, open-source models like Llama or Qwen series are solid choices, for text handling and coding.
In general, the model should be chosen based on the task and the underlying purpose. As discussed earlier, the Cursor team has released a model selection guide to help users identify the right model for their scope of work at a high level. The selection tree from their guide is shared below.

In case of AI code editors like Cursor, Windsurf, and VSCode, we can select models based on our purpose. This table could help with model selection based on our coding purpose, in the Editors.
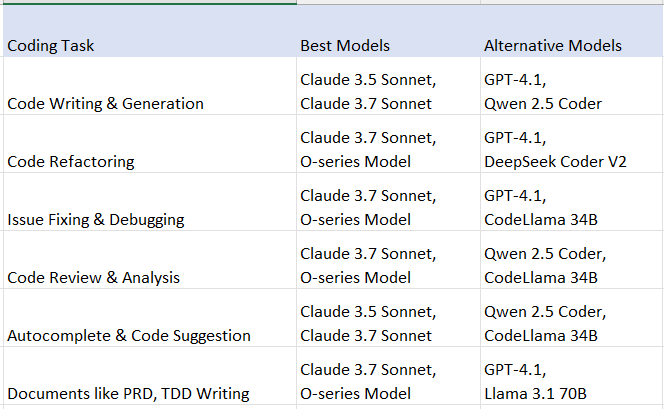
These recommendations are based on my testing experience across different providers. Always test models with your specific use case and data before making final decisions.
Most models are multimodal now. They can handle text, images, and audio inputs, and generate various output formats too. We should be clear on what should be our input to the model and what should be the output from the model, which is our next topic to be discussed.
2. Identify Model Input Type
Once we know the purpose of the model, the next question is, what are we feeding it?
This might seem obvious, but different models handle different types of input. Some are text-only champions, while others are multimodal powerhouses that can juggle text, images, audio, and video all at once.
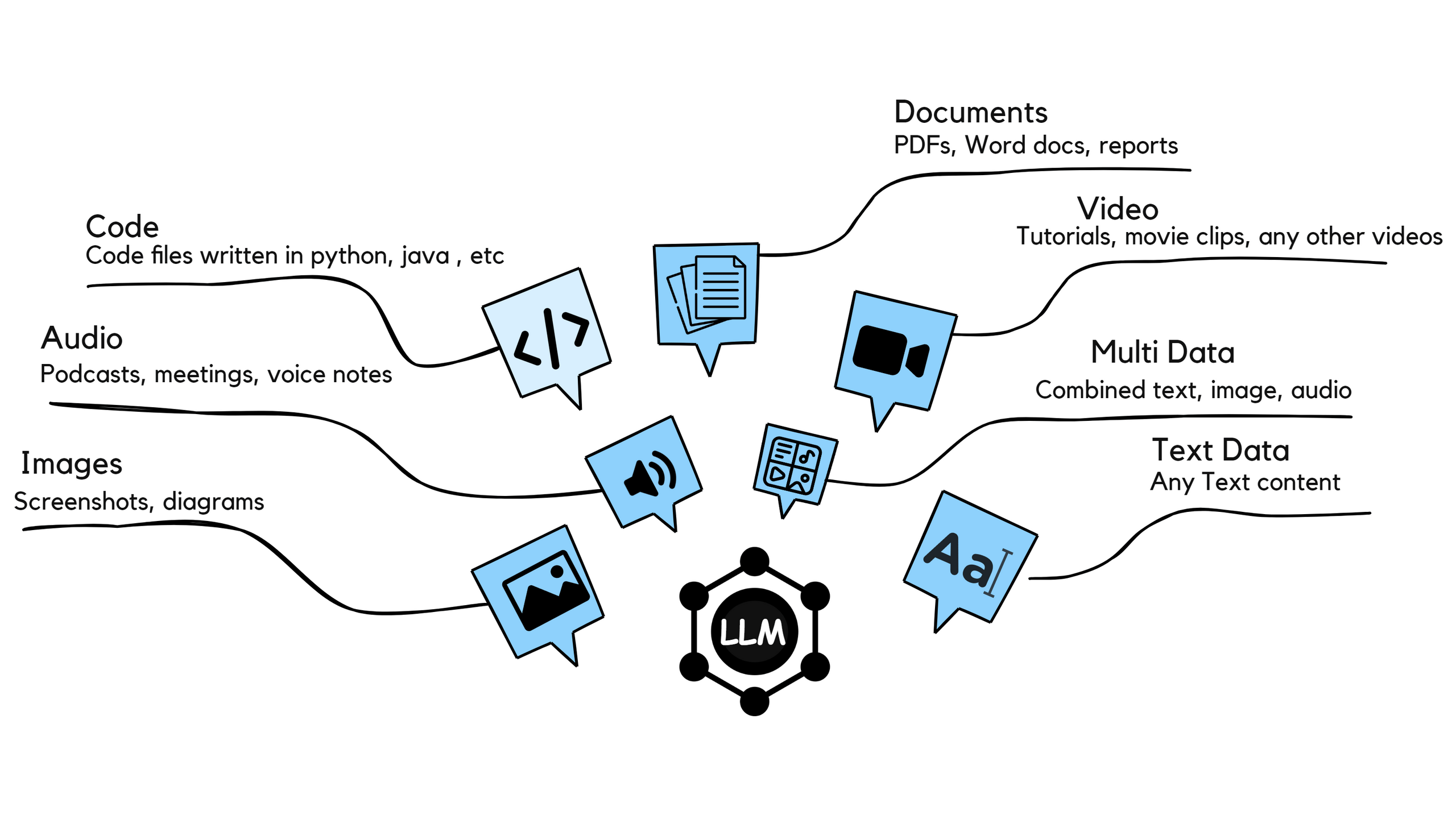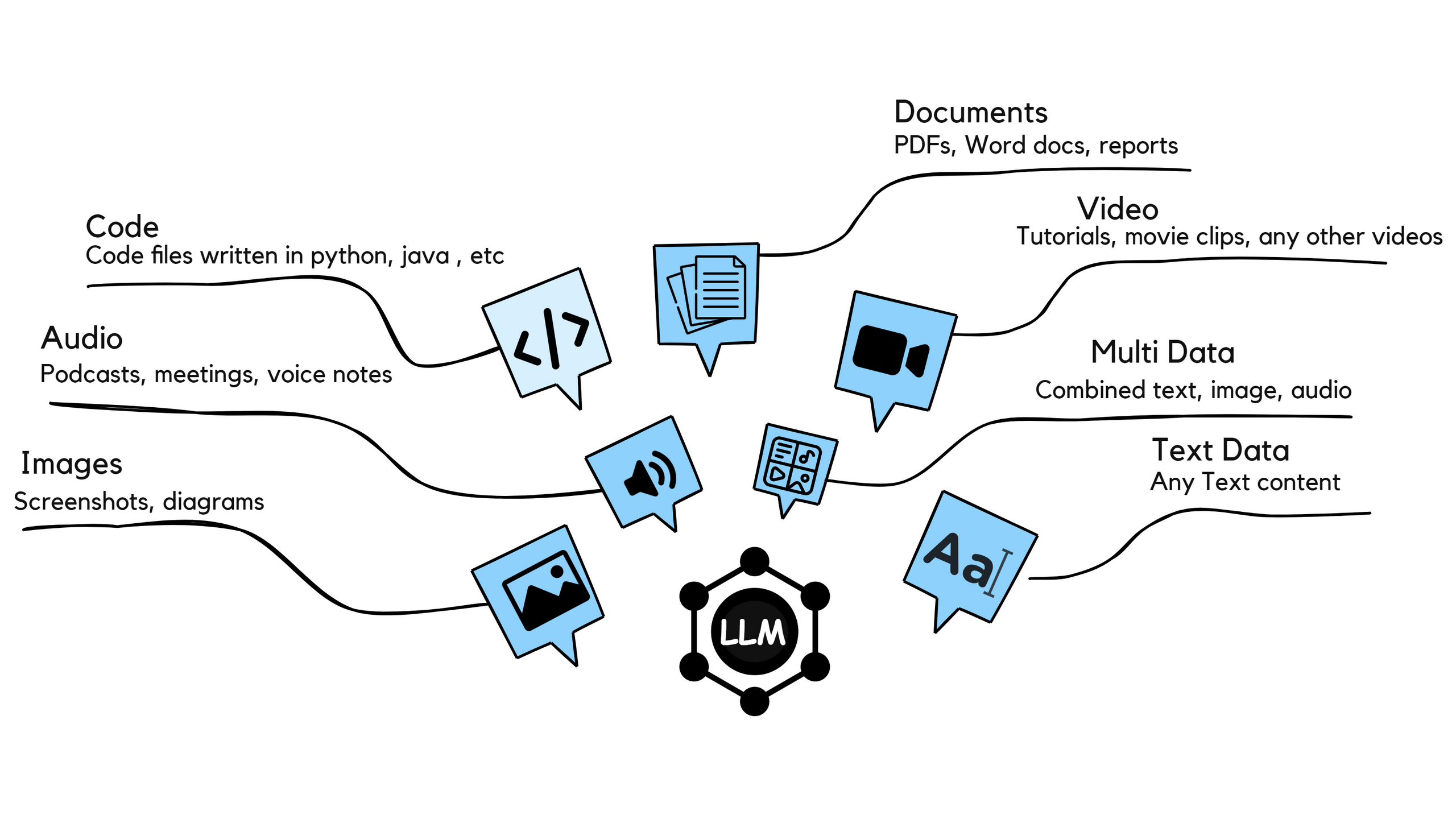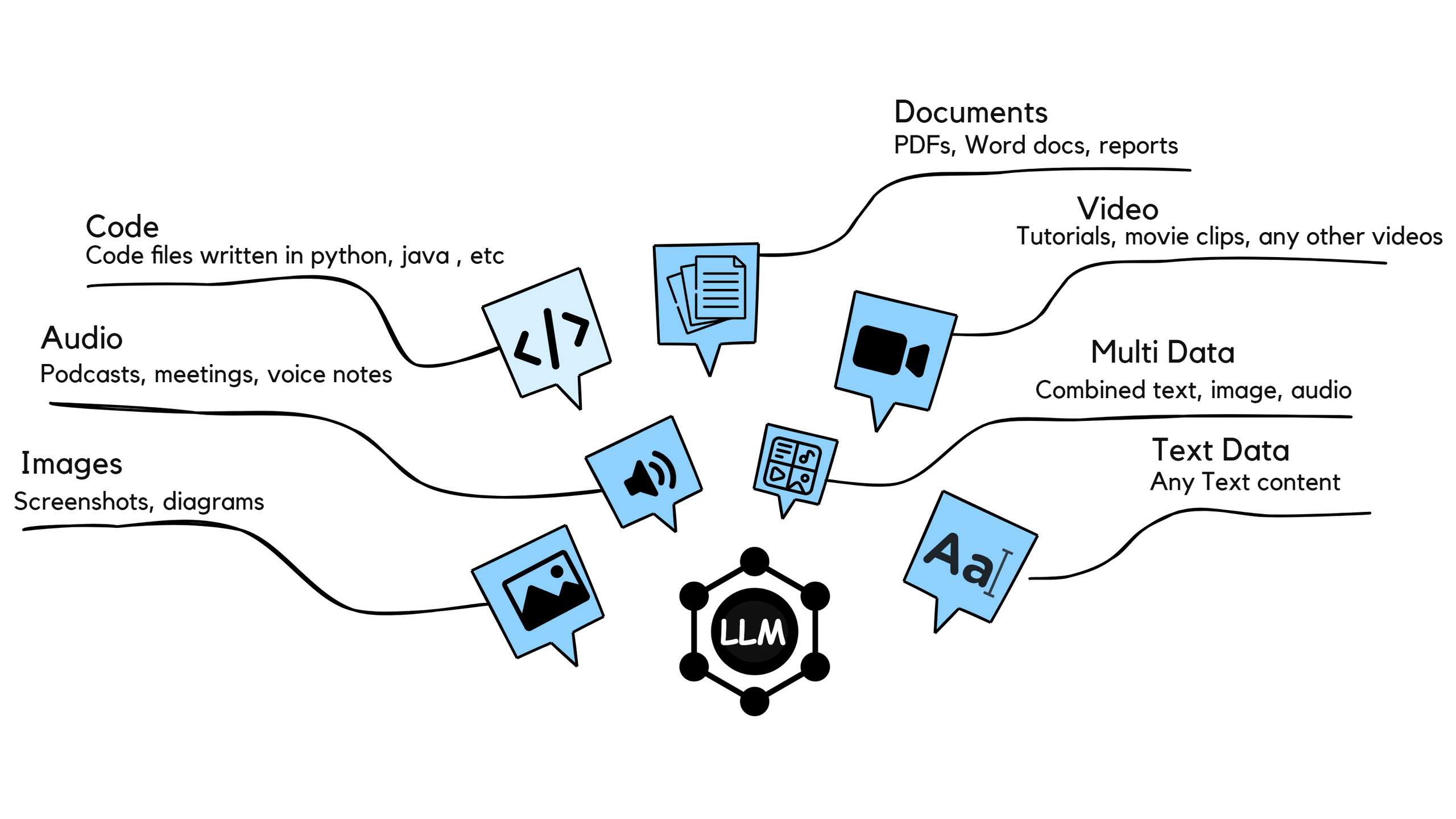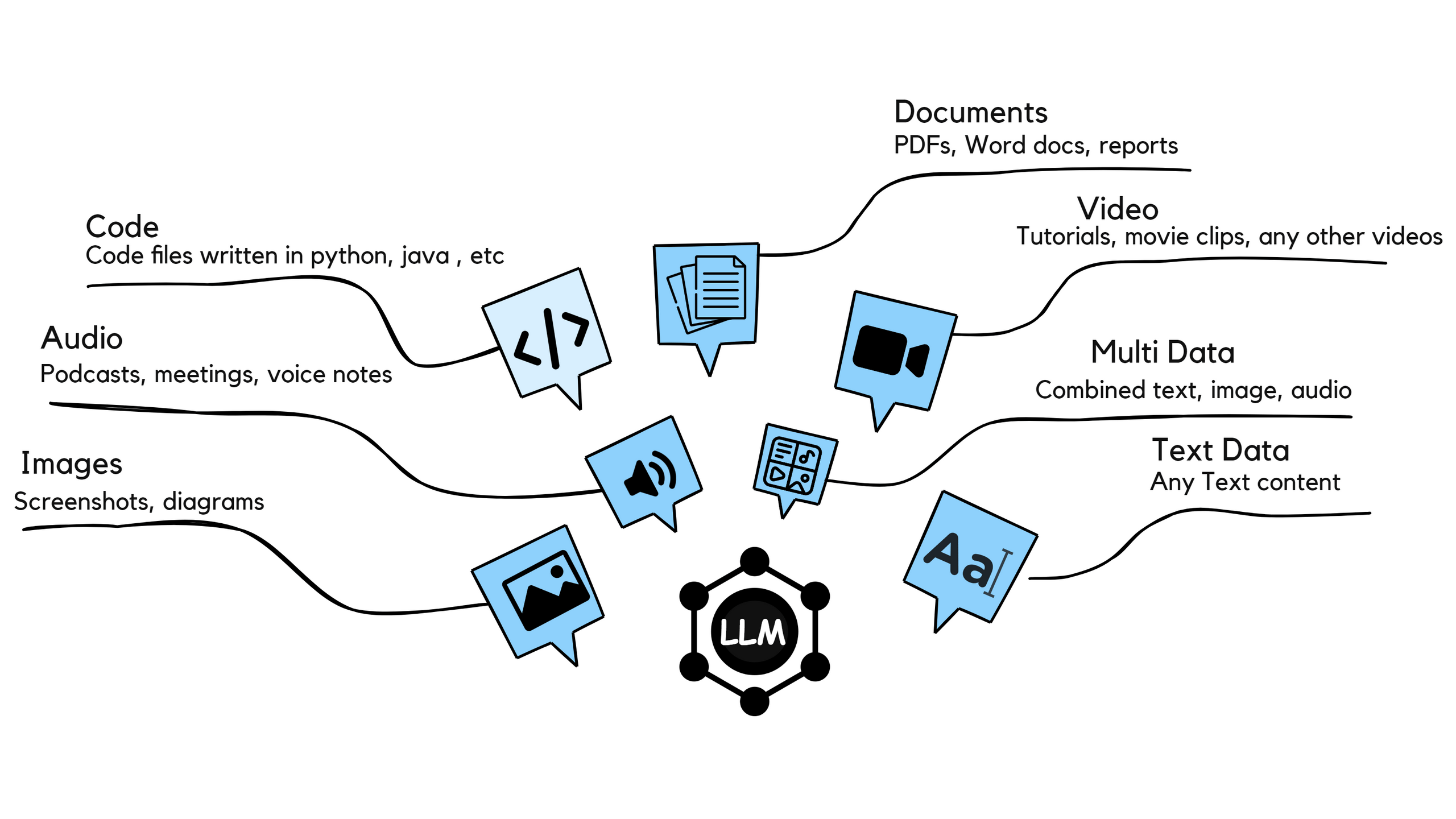
Look at the diagram above. Modern LLMs can process pretty much anything thrown at them, code files, podcasts, screenshots, PDFs, even video tutorials. But just because they can, doesn't mean they're all equally good at it.
For instance, if we are mainly dealing with text documents and occasional images, we don't need the most expensive multimodal models. A text-focused model might be faster and cheaper. On the flip side, if our workflow involves analyzing video content, transcribing audio, and extracting text from images, then we may need a multimodal model.
Consider Input Complexity, Not Just Type
Here's what most people miss. The size and complexity of the input matters too. Processing a single page of text is different from analyzing a 200-page research paper. A quick audio clip needs different handling than a 3-hour podcast.
The key is being honest about what we are actually putting in. We should not get caught up in everything a model can theoretically handle, we should focus on the model that is very good at handling the input that we are planning.
For text related input: Smaller models like GPT-4o-mini or Claude 3.5 Haiku often work just as well as their bigger siblings and cost way less. In open-source options Llama models work for pure text tasks.
If we deal with coding: Claude Sonnet excels at code generation and debugging. In open-source alternative, Code Llama or Qwen Coder are surprisingly competent alternatives, which can be self-hosted.
For multiple file types (PDFs, images, audio): Multimodal models like GPT-4o or Gemini Pro make our life easier. In open-source llama vision models are available.
For visual content creation: Specialized models like Flux often outperform general-purpose models for pure creative work. Open-source alternative like Stable Diffusion XL is solid for image generation.
If the input is audio: OpenAI's Whisper is still the gold standard for extracting subtitles and transcripts. For pure transcription, dedicated models like Whisper or Azure Speech Services are more accurate, and the good news is Whisper is already open source.
3. Identify Input Size
With input type clarified, the next important question is, how much data will we process in a single request?
This one is important. In text-based models there is something called, Context window. Think of it like the model's capacity limit. Everything we feed it in a single request needs to fit within this window.
Models with bigger context window isn't always better. I have seen people pay premium prices for 1 million token models when they are only feeding it a few paragraphs. That's like renting a pickup truck to carry a single grocery bag. But go too small, and we'll hit walls. Try analyzing a 50-page report with a model that can only handle 10 pages?
The key is finding a model whose context window matches the typical input size.
Here's what the context window size across popular models and notice how the prices scale with those token limits.

If we are doing customer support Q&A, 128K tokens is overkill. If we are analyzing legal contracts or research papers, we may need something bigger.
1 token is roughly 0.75 words. So 128K tokens are about 96,000 words. Don't fall for the "get the biggest context window just in case" trap. Start with what is needed, test it, then upgrade if necessary.
If we need to calculate number of tokens in our input, there are more websites which can do free. Try the token calculation in this OpenAI page.
4. Define Model’s Priority
By now, we know what our model needs to do, what type of data we will feed the model, and how much we will process at once.
And here is the reality nobody talks about in AI marketing brochures. Every model is a compromise between three things, speed, accuracy, and cost. Get great speed, or high accuracy, but be ready to pay more.
Here's how the landscape breaks down in practice,
General purpose models like GPT-4, Claude 3.5 Sonnet, and Llama series are the workhorses. They give solid performance for most tasks and respond quickly, as they get the job done for 80% of use cases.
When we need high accuracy, we go for reasoning models. If we need the strongest reasoning and have the budget, we can go for o3, it's OpenAI's most capable reasoning model. But if we want reasoning with both speed and budget, o4-mini is our sweet spot. Think of o4-mini as reasoning-lite, we still get the step-by-step thinking, just not as deep, but at a fraction of the cost.
The diagram below shows how to navigate these trade-offs,
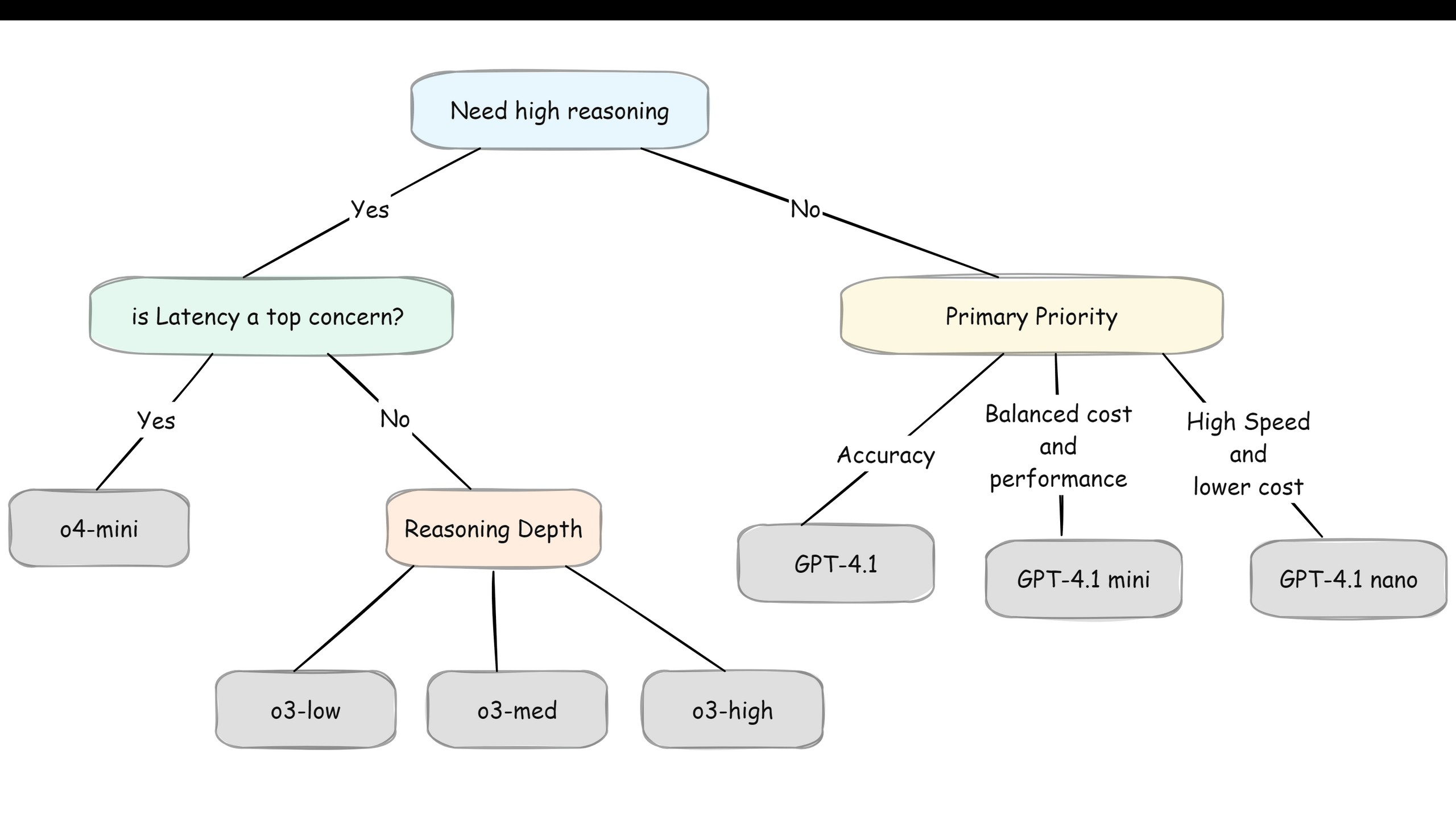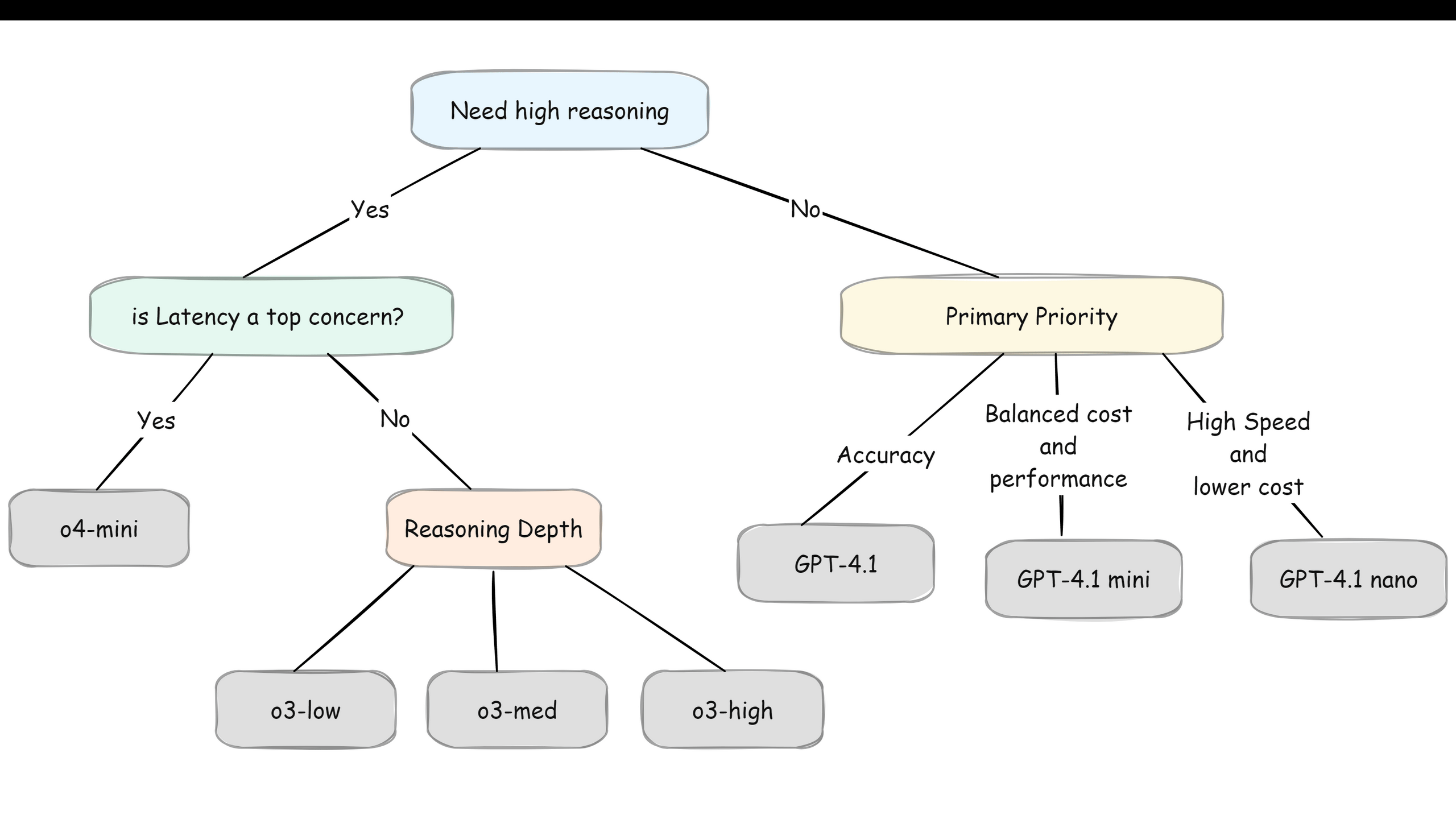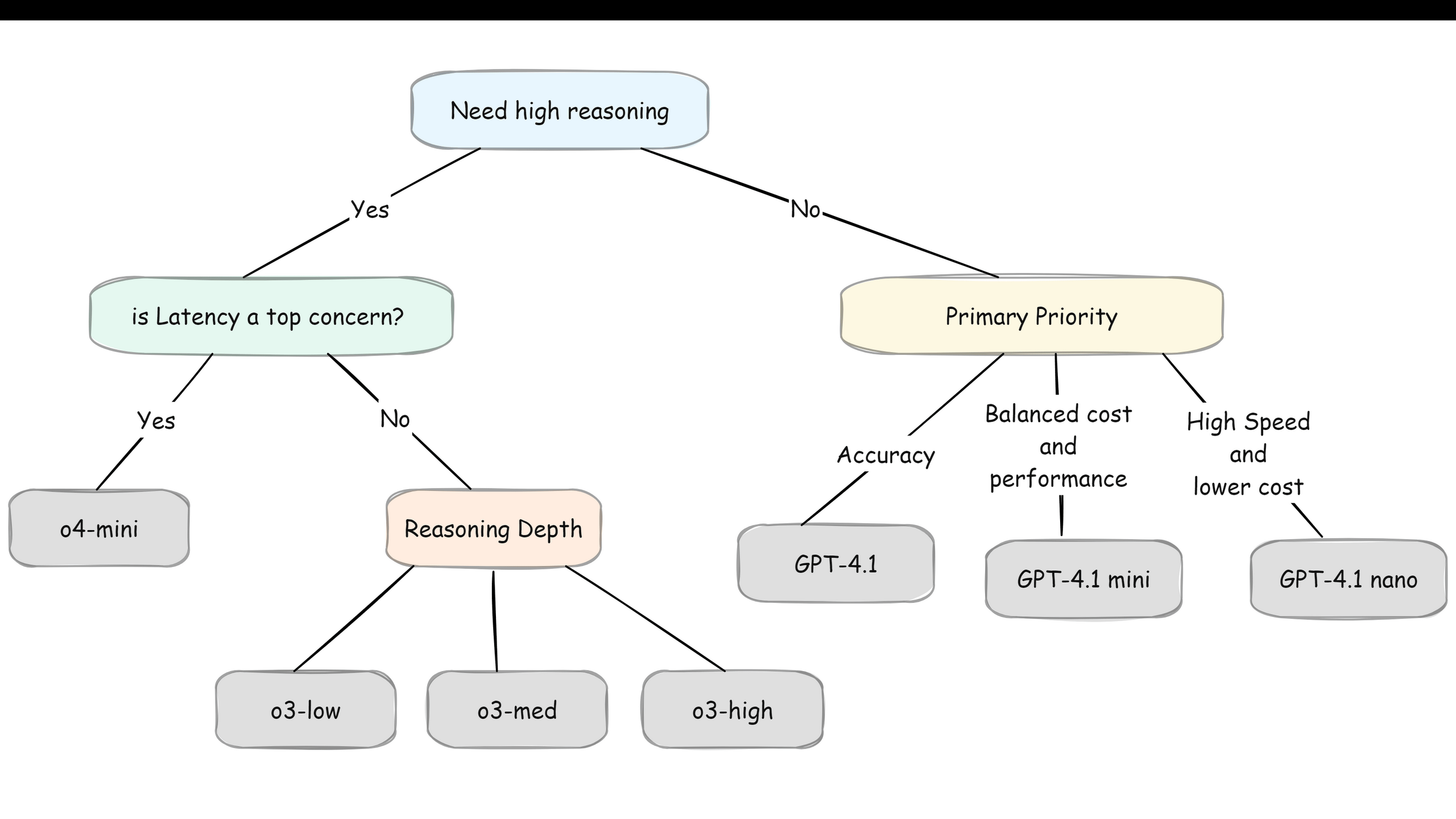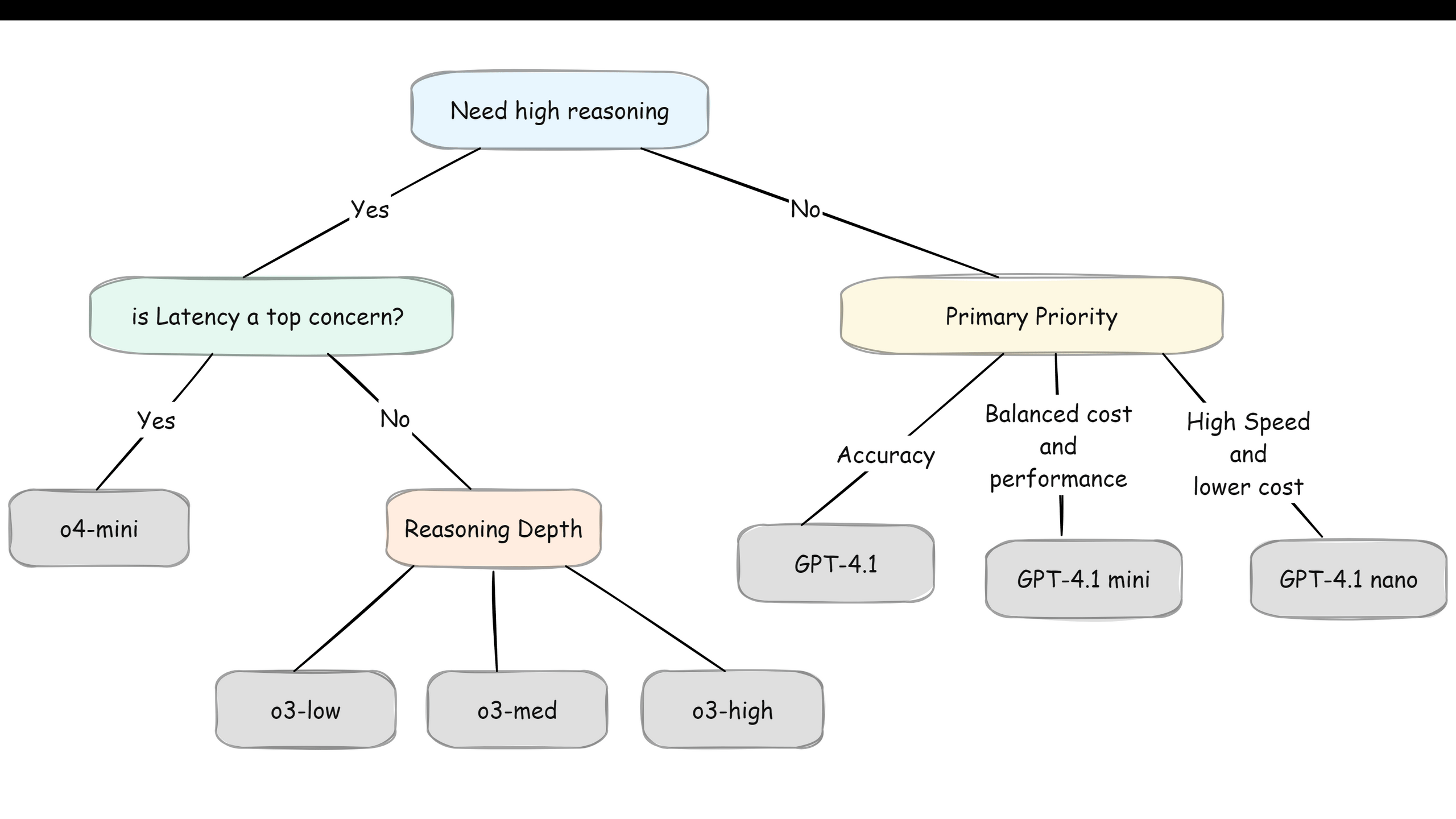
Note: OpenAI's reasoning models let us control their thinking depth with reasoning effort settings (low, medium, high). High thinking = better accuracy but slower speed and higher cost.
Here's something interesting. Anthropic's Claude 3.5 Sonnet can pull double duty. By default, it's a regular fast model. But enable the "thinking" parameter, it becomes a reasoning model. Same model, different behavior. Pretty neat solution if we want flexibility in one model rather than switching between different ones.

Here's what I've learned. we don't need a reasoning model to summarize emails or generate social media posts. But for complex code review, financial analysis, or legal document parsing? The extra accuracy is worth the wait and cost.
Bottom line: Match priority to the use case. Don't use a Ferrari to deliver pizza.
5. Choose the Customization Level
The purpose, input data type, size, and performance priorities are now defined. Before we discuss data privacy considerations, let us address how much we need to customize the model.
Most people think it is a binary option, use it as-is or train from scratch. That's not true. we have got a whole spectrum of options, and most businesses benefit from landing somewhere in the middle.
Here's how this affects the model choice. If we don't want customization, we can stick with API-based models from providers like OpenAI, Anthropic, and Google. If we need customization, our options expand to cloud-hosted models, specialized finetuning providers, or open-source models for complete control.
Ready-to-use models are exactly what they sound like. Hit the API, get responses. No configuration, no training, no headaches. OpenAI's API, Claude's API, Google's API, they all work out of the box for most of the cases. Perfect if we just want to get stuff done without getting so deep into the model.
But finetuning helps the model to adapt to the specific needs. We can finetune both proprietary and open-source models.
With open-source models like Llama, Mistral, or Qwen, we have two paths. we can finetune them on our own if we have the GPU hardware and technical expertise. Alternatively, platforms like Fireworks AI, Together AI, provide GPU infrastructure with user-friendly interfaces, just upload the dataset, configure settings, and they handle the actual finetuning. we still get the complete model weights and full control, just without the hardware headaches.
AWS, Azure, and GCP offer finetuning for both proprietary models and open-source models. We get the convenience of not managing infrastructure while still customizing the model.
Finetuning is actually expensive, time-consuming, and probably overkill unless we are doing something very specialized. The level of customization we choose will influence our deployment options also, which we will cover next.
Start simple. Use an off-the-shelf model, see what works and what doesn't, then consider customization if needed. The model choice is not permanent. We can always shift to the best model as we grow.
6. Choose Model hosting and Privacy
After all, we arrive at the last crucial question. "Where will we deploy our model?", which indirectly means, where will the model process the data? This is not just a technical decision. It is about balancing security, control, and practicality.
The Three Deployment Options:
API-based models (like OpenAI, Anthropic, Google) process the data on their servers. The prompt goes in, response comes back. Most reputable providers say they don't train on the data, but it's still traveling through their pipes. For casual use? Probably fine. For sensitive business data or personal info? Maybe not so much.
Cloud-hosted solutions give us more control. We get the convenience of APIs but with more security controls, data residency options, and compliance features. Our data stays within the cloud environment.
Self-hosted models are the ultimate in privacy. Everything runs on our own hardware. No data leaves the building. But they also max out on cost, plus we are also responsible for everything like hardware, updates, security, performance optimization. Complete control comes with complete responsibility. Open-source models like llama fit in this category.
Here's how these three approaches compare across all key factors.

Based on the deployment option, the models will get filtered. My opinion is, try to start with API-based for prototyping, then move to cloud-hosted for production. If data needs more security, go for self-hosting.
Evaluate Model Performance:
Now that we've worked through all questions about purpose, input type, size, priorities, customization, and hosting, we likely have two or three potential models that fit our requirements. Say for example, we have a normal text-related task for which we have narrowed down to GPT-4.1, Claude 3.5 Sonnet, and Llama 3.2. How to choose between them? This is where evals come into the picture. And evals are surprisingly often all we need.
Evaluation frameworks provide a systematic way to test LLM performance. The below diagram can explain the typical flow.

There are many frameworks available for evaluating LLMs. Some popular ones include, OpenAI Evals, DeepEval, RAGAs, Opik by Comet, etc.
I have evaluated Claude 3.7 Sonnet for a Question Answering task using DeepEval. Here's the test score.

In a similar way, we can evaluate different models for our specific task and then decide which one best suit our needs.
Eval Frameworks are deep enough to deserve their own dedicated post. Expect one from us soon where we'll dive deeper into various evaluation methods, metrics, and how to set up own evaluation pipeline for different use cases.
Put It All Together
Alright, we've covered a lot of ground. Let me quickly summarize the path we have laid out for Choosing the right LLM,
Identify the purpose - What specific task do we need the model to perform?
Identify input types - Will we be processing text, images, audio, video, or multiple formats?
Identify input size - How much data will be fed to the model per request?
Define Model’s priority - Speed, accuracy, or cost?
Choose customization level - pre-trained or finetuned?
Choose the hosting and privacy - API-based, cloud-hosted, or self-hosted?
Answer all these questions and use the evals framework to evaluate the models to find the best one.
Another easy way is, answer our framework questions honestly, frame them like below prompt (it’s an example) and put it in ChatGPT. (I used o3 reasoning model to address this prompt)
"I am building an agent to analyze research papers and create consolidated summaries. I typically process 5 research papers at a time, each containing approximately 5,000-10,000 words. My input is only text (PDFs converted to text), and the output will be a summary in text. I'm fine with API-based models since these are public research papers with no privacy concerns. Processing time isn't critical - I can wait 30-60 seconds for quality results. Accuracy is more important than speed for this use case, also start with models having minimum cost. Based on these requirements, which model would you suggest?"
See what we have got,

Let ChatGPT do the heavy lifting, and all the options will be laid out before our eyes. Now let us evaluate these models with the framework we covered and identify the one that has highest score and use it.
If this framework saves someone from the overwhelm of countless options, this blog has done its job. The goal was not to hand the perfect model, but to give a systematic way to think about the choice.
Work through these questions, eliminate models that don't match, and choose one that feels about right. Test it and use it.
You've got this.
Happy Learning…