

The AI revolution is here, and it is impacting most areas of Software Technology. There are many posts about current wave, however, in this post we would like to talk about the common jargons that are used randomly by most folks in this domain.
While many throw around these terms casually, understanding their true meaning is essential for anyone working in the domain. Let's break down these common AI terms that are often used randomly in conversations, helping you move beyond buzzwords and understand their actual role in modern AI systems.
Some of the LLM terms we use all along the way is given in wordcloud.
let's get something straight - these aren't just buzzwords. Each of these terms has a specific meaning and purpose in the AI ecosystem.

The most frequently used AI terms are organized in a way that makes sense. The picture is colored into five main territories. And yes, we've packed even more AI terms in the blog than what fits in this neat little map - consider this as your visual starting point!
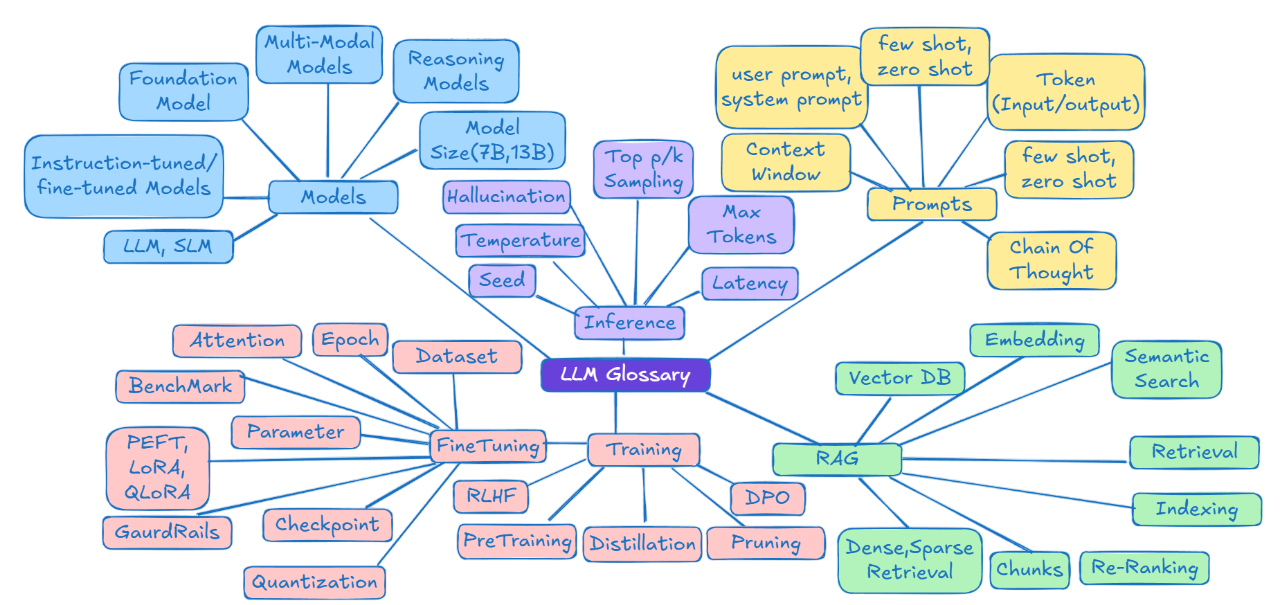
Not to worry if some terms are unfamiliar - detailed explanations follow in the next sections
Blue zone: Terms related to AI model types, architectures, and sizes.
Yellow zone: Terms used when we interact and guide AI models.
Purple zone: Terms related to how models process inputs and generate outputs.
Pink zone: Terms for model training and tuning and optimizing AI models.
Green zone: Terms used when we connect models with external knowledge sources (RAG)
For anyone new to AI, understanding these basic relationships is key to grasping how modern AI systems function, without getting lost in technical jargon.
Models:
When we talk about Models in AI, it covers a wide range of models generating text and models creating images and videos. Large Language Models (LLMs) specifically focus on text understanding and generation, falling under Natural Language Processing (NLP).
Before we jump into jargons, Let’s explore some models driving the AI tools you use every day.
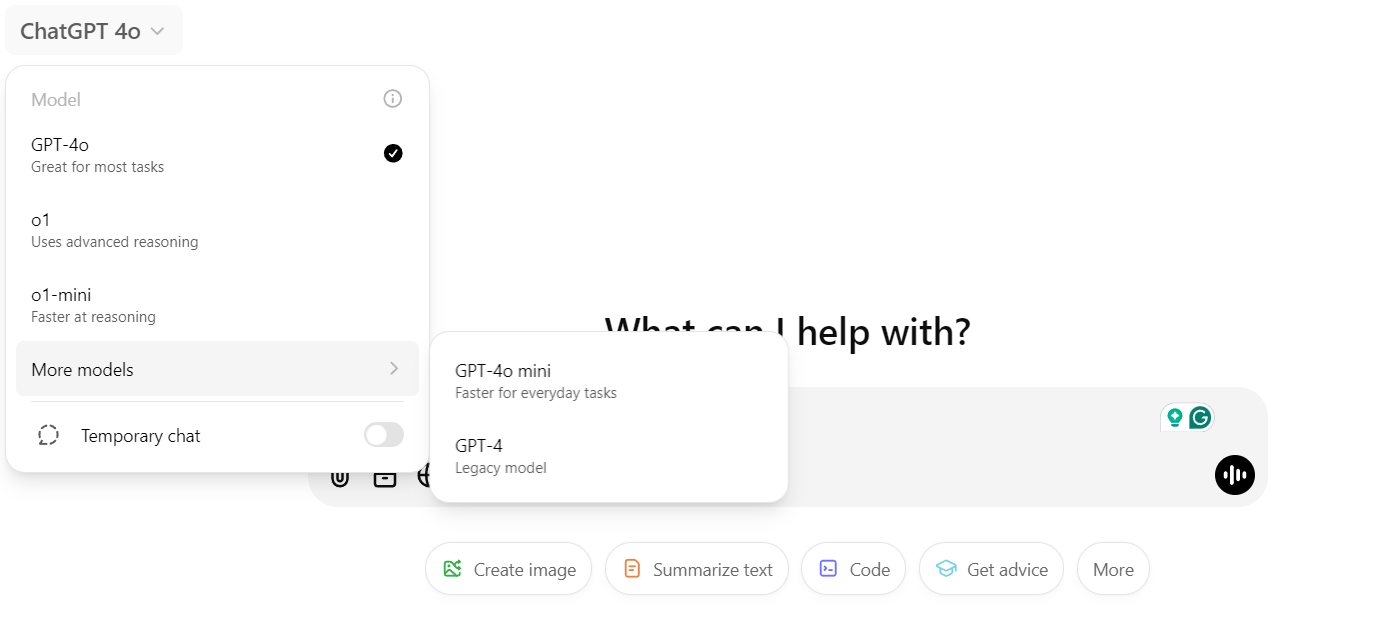
Used ChatGPT? You’re engaging with models like GPT-4, GPT-4o, o1 and their mini versions. all operating behind the simple chat interface.
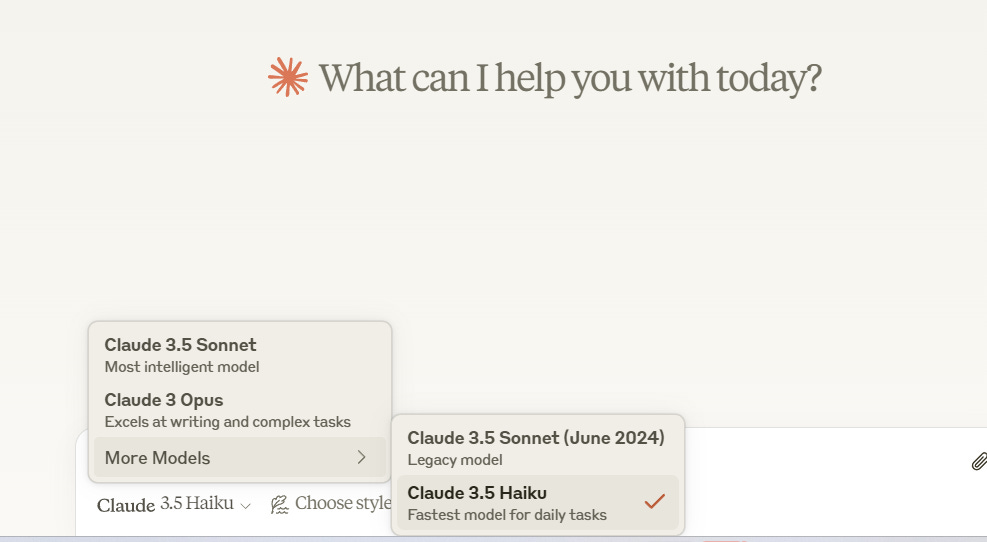
Worked with Claude? behind its clean interface runs models like Claude 3.5 Sonnet manages general tasks, Claude 3.5 Haiku delivers fast and efficient responses, and Claude 3 Opus handles complex challenges.
These real-world examples highlight how the models we’ve discussed are the backbone of the AI tools we rely on daily.
Let's start with the Blue Zone, which covers model-related terminology.
Base Models (Foundation Models):
They are Large AI models pre-trained on massive datasets, which gives them broad capabilities in understanding and generating text, images, code, audio, and video. They serve as the starting point from which more specialized models can be created through additional training or fine-tuning. Examples: GPT (Generative Pre-trained Transformers -for text), -the base model behind all GPT versions like GPT-4o, DALL-E , Stable Diffusion (for images), AudioGen (text-to-audio), Whisper (audio-to-text)
Fine-tuned Models:
Models trained for specific tasks using domain data. A general language model fine-tuned on legal documents becomes specialized in legal writing. Task is fixed during training - like a model that only does legal document analysis.
Examples: CodeLlama (tuned from LLaMA for coding), CodeQwen (tuned from Qwen for coding
Instruction-tuned Models:
Models trained to follow different instructions at runtime.
Their training dataset will be like below
Instruction: "Translate this text to Spanish"
Input: "Good morning"
Output: "Buenos días"
Instruction: "Write a summary"
Input: "The cat sat on the mat and watched the rain fall on the window."
Output: "A cat observed rainfall while sitting on a mat."Both Finetuned and Instruction tuned models aren't built from scratch - they're tuned versions of Base Models.
Multimodal Models:
It is a Model (AI) that can accept and process multiple types of data in input/outputs.
Example: OpenAI's ChatGPT 4o, Google's Gemini - They both accepts various inputs, including text, images, and documents, and can generate outputs in different formats, such as text-based answers, images.
Reasoning models:
These are latest models in the field, it thinks critically, solve problems step-by-step, and self-correct to provide accurate solutions. They use a Chain of Thought (CoT is covered in upcoming sections) to handle complex, multi-step tasks effectively.
Examples: OpenAI’s O1, F1-Preview, R1-Lite-Preview, QwQ-32B-Preview, the very latest Sky-T1-32B-Preview
LLM, SLM:
LLM is Large Language Model, and SLM is Small Language Model. The main difference between them is their size. LLMs typically contain hundreds of billions of parameters (like Llama-3.1 with 405B, PaLM with 540B) - and of course models like GPT-4 and Claude trained on billions of parameters though exact numbers aren't publicly disclosed. These models are capable of complex tasks but resource heavy (means need more GPU to run).
SLM contain fewer parameters (Google’s Gemma, Microsoft’s Phi family of models Phi-3-mini (3.8B), Phi-3-small (7B)), making them more efficient for specific tasks. Any model with similar smaller sizes (3B-7B range) fall under this category.
Model Size (7B, 13B, etc.):
Models come in different sizes, measured by their number of parameters or neural connections. When you see a 'B' in model names, it indicates billions of parameters - for example, 7B model means 7 billion parameters working together like interconnected neurons to process and generate text. Generally, more parameters allow the model to understand more complex patterns.
After understanding different models and their sizes, let's look at what's actually available for developers to use. Models come in two categories - open source and proprietary:
Open-Source Models: Check out all open-source models here. (Meta-Llama, Qwen, etc.…)
Proprietary Models: Accessible through their platforms and APIs (OpenAI, Anthropic’s Claude, Google’s Gemini)
AI Platforms offering models:
Let's look at some platforms where you can access these models. Beyond the major cloud providers -AWS, Azure, and GCP, there are specialized platforms like Replicate, Fireworks AI, and Together AI that make model access simpler. You can simply use their APIs or host your own models.
For those who prefer running models on your own (either local or on your own server), Ollama is a good option. It lets you run open-source models right on your machine.
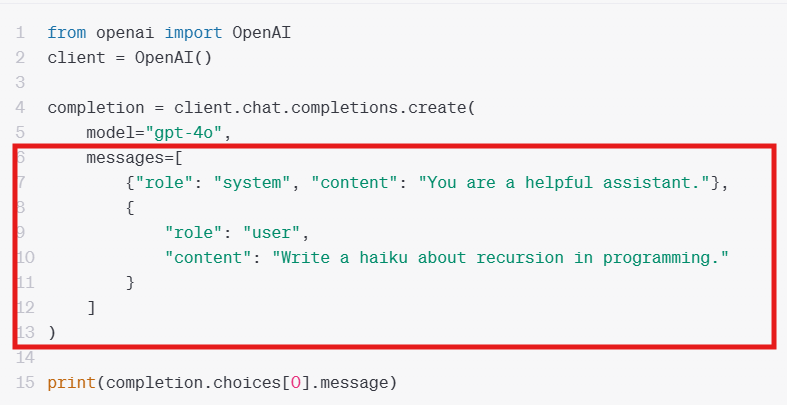
Prompt: Speaking to LLM:
A prompt is the input or instructions given to an AI model to get the response.
Types of Prompts:
System Prompt: Instructions that set the model's role and behavior
For example: Telling it what it is ("You are a helpful assistant")
User Prompt: Questions from the user.
For example: User provide a prompt "Write a story"
Prompt Techniques:
Ways to give clear and effective instructions to AI models.
Zero-shot:
Providing direct prompts without any examples for the model to follow.
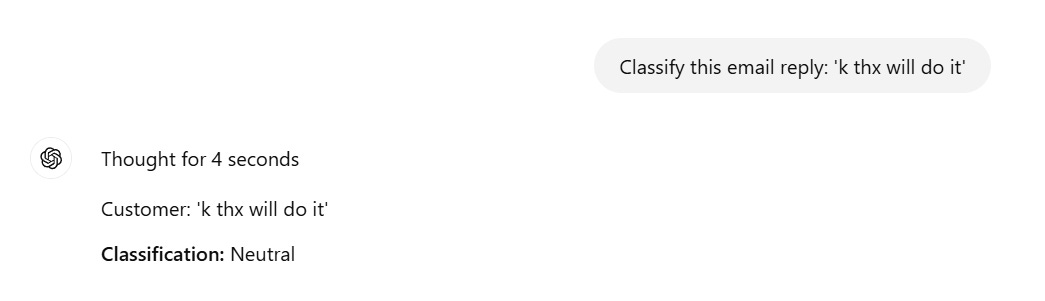
Few-shot:
Giving prompts along with a few examples to help the model understand and follow the task better.
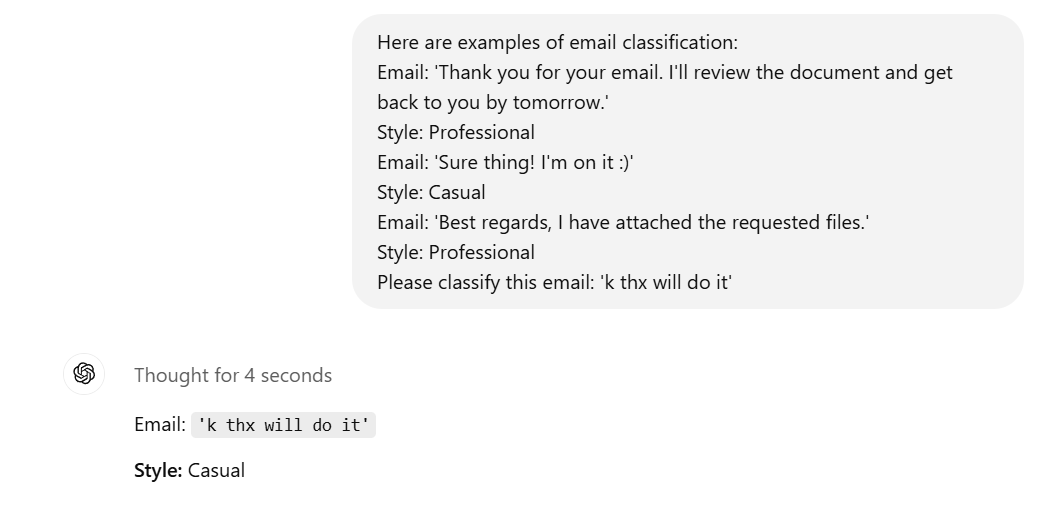
Chain of Thought:
Chain of Thought (CoT) prompting is a technique that helps models solve problems step by step. See below to understand the difference between a normal prompt and CoT Prompting.
Normal Prompt:
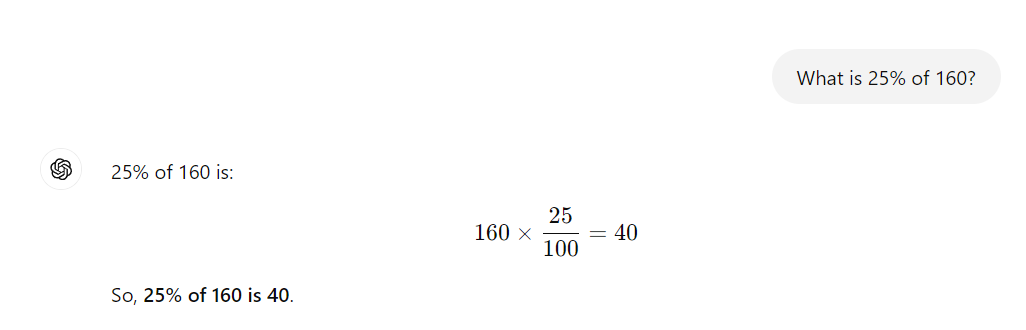
CoT Prompting:

Reasoning models like o1 showed their Chain of Thought (how they were thinking by breaking problems into steps) earlier. Though o1 doesn't show this process anymore due to policy changes, it gave us a great example of how AI models can tackle complex problems step by step. Let's look at how o1 used to show its reasoning
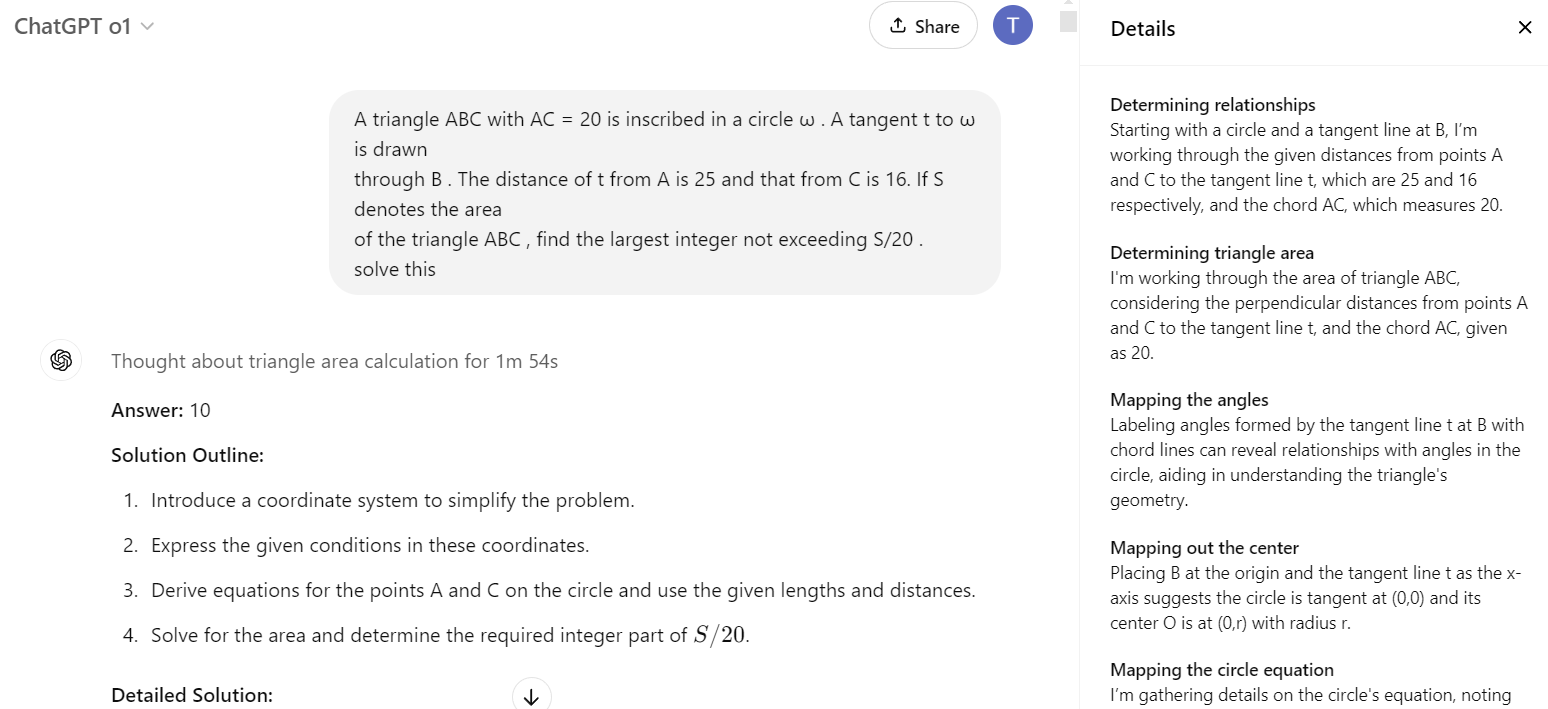
This above example is from o1's earlier days when it would show you its thinking process. Now, with updated policies, it just gives you the answer without revealing how it got there - though it's still using the same step-by-step reasoning behind the scenes.
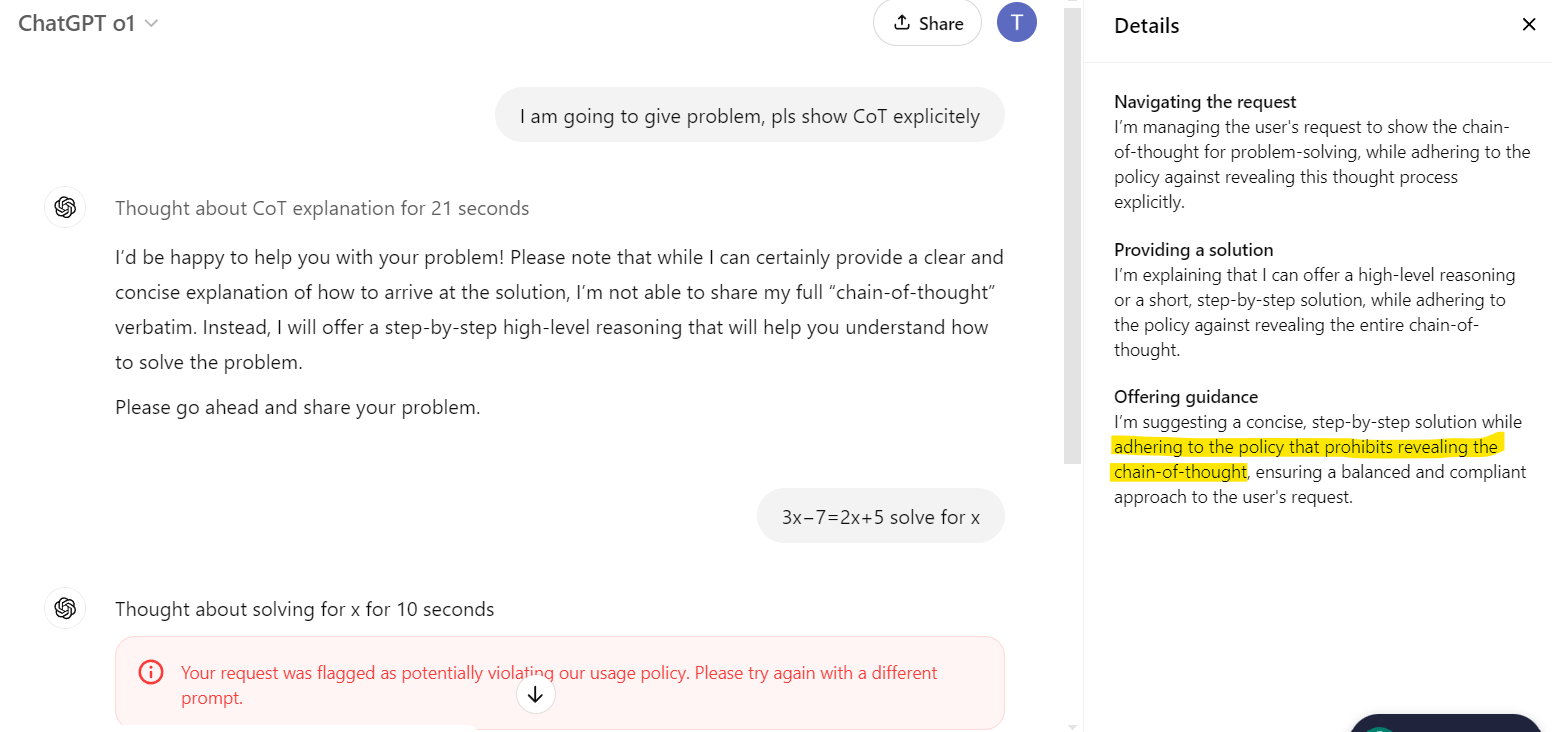
Token
AI models process sentences as tokens, which are the smallest units of text. On average, one token equals about 4 characters or roughly 3/4 of a word, meaning 100 tokens is about 75 words.
There are libraries that convert sentences into tokens, but they aren’t very strict. For example, see below: common words like "the" or "model" might be treated as single tokens no matter their length, while longer or more complex words can be split into multiple tokens.
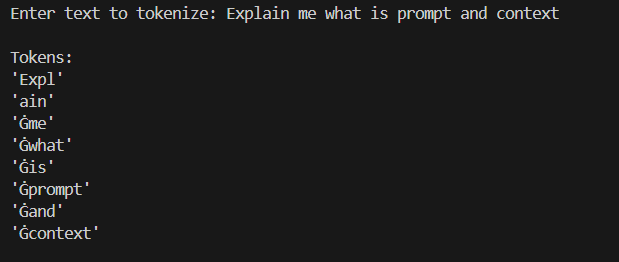
Let us see how Tokenizer break sentences into tokens so the model can process them.

The sentence "Explain me what is prompt and context" is tokenized like below: The ‘G’ symbol represents space in the GPT Tokenizer.
Context Window:
Context Window is the maximum amount of tokens a model can handle in a single interaction. When building AI applications, choosing the right context window size is crucial. For applications that need to process large amounts of text - like code analysis tools - you'll want models with large context windows (models like Claude with 100K tokens or GPT-4 with 128K tokens work well here). But for simpler applications like basic chatbots, models with smaller context windows (like GPT-3.5 with 16K tokens) would work just fine. Understanding these limitations helps you pick the right model for your specific needs.
Measured in tokens.
The size of the context window depends on the model:
GPT-4: 128K tokens (~96K words)
Claude: 200K tokens (~150K words)
GPT-3.5: 16K tokens (~12K words)
Inference:
Inference is how models turn inputs into answers using their training knowledge. Think of it like this: when you ask ChatGPT a question, the actual process of it understanding your question and creating a response is inference. The quality and style of these responses can be controlled through various inference parameters like temperature and top-k sampling, which is discussed below.
Temperature: Think of it as a creativity knob.
Turn it up: Model gives more creative and varied answers.
Turn it down: Model stays more focused and consistent replies.
Top-K/Top-P: Settings that control word selection. Lower values make responses more focused and predictable, higher values allow more creative and diverse outputs.
Max Tokens: Sets a cap on the length of the model’s response.
Helps manage time, cost, and keeps the answer within limits.
Latency: The time the model takes to respond.
Depends on the model’s size and hardware, similar to a “thinking time.”
Seed: A number used during response generation, Using the same seed gets you the same result every time - imagine using seed 123 and the prompt "create a blue butterfly", then using the same seed 123 but changing the prompt to "create a red butterfly". You'll get the exact same butterfly design, just in a different color.
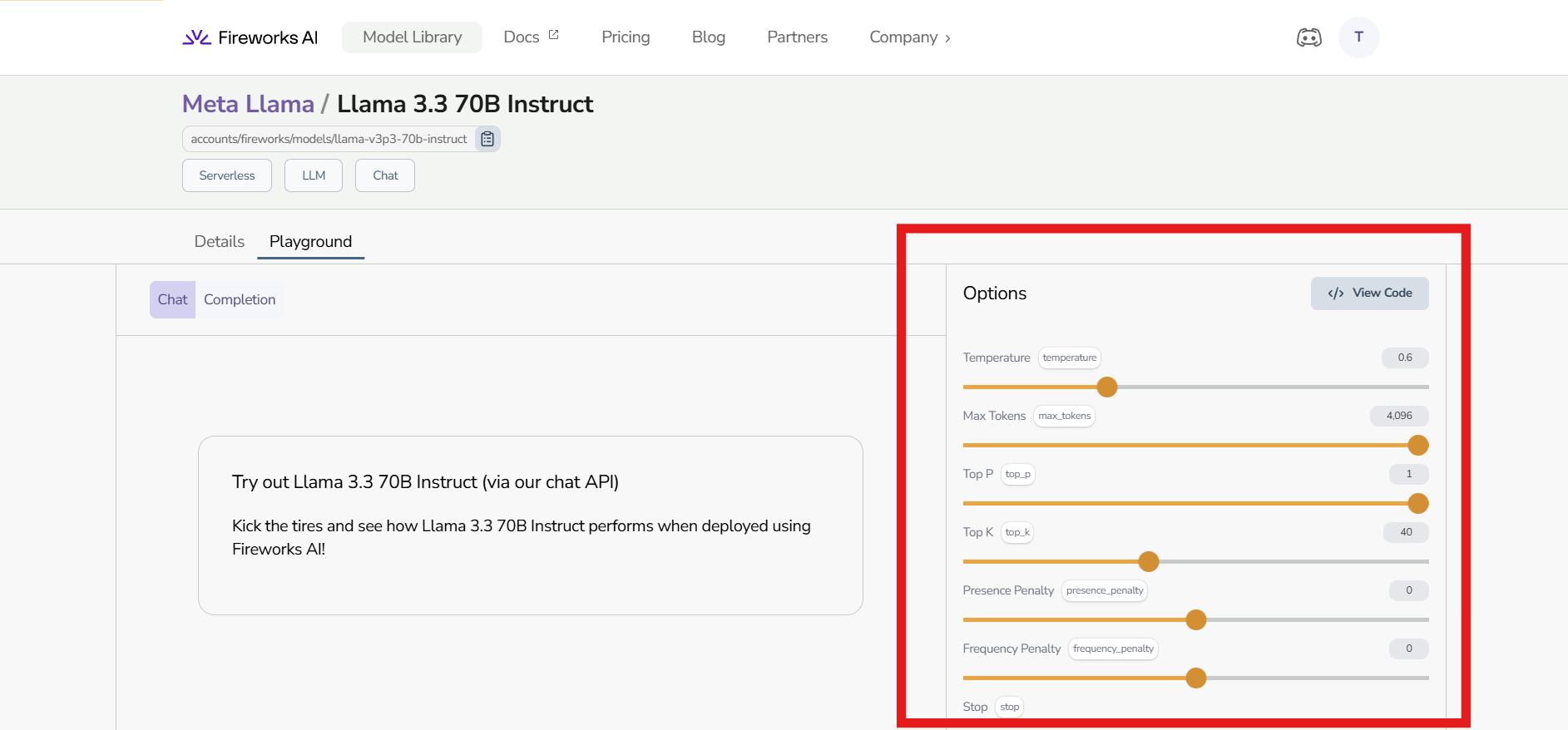
These parameters are commonly found in AI platforms and let you customize how the model generates responses. Below is an example from Fireworks AI’s Playground, where you can adjust the inference parameters to refine the model's behavior and output.
After looking at parameters we can adjust during inference, it's important to understand a key challenge in AI responses - hallucination. Unlike temperature or max tokens, hallucination isn't something we can simply tune with a slider, but it's a crucial concept to understand when working with AI models.
Hallucination:
Hallucination in AI models refers to generating false information that sounds convincing but isn't real. When models create content, they might mix training data in unexpected ways, resulting in responses that appear logical and well-structured but contain incorrect or non-existent information - making fact-checking crucial when accuracy matters.
In the early stages, it was easier to notice AI models producing hallucinations. Nowadays, models are better trained to acknowledge when they might provide inaccurate information and advice users to verify details from other sources. Claude, in particular, excels at handling this responsibly.
The art of inference is about striking the perfect balance—set it too strict, and you lose creativity; make it too flexible, and you risk inconsistency.
Pre-Training:
Pretraining is the phase where a model is built from the ground up, laying the foundation for everything it will learn later. During this stage, the Base Model is trained on vast amounts of data like books, websites, and articles to grasp general language patterns, facts, and concepts. This broad knowledge prepares the model for more specialized tasks through fine-tuning.
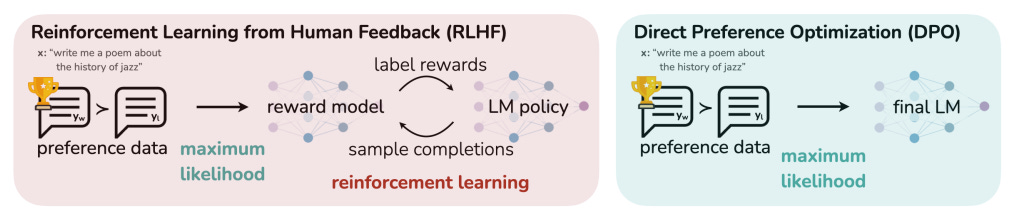
RLHF (Reinforcement Learning with Human Feedback):
RLHF is guiding a model by giving it rewards for good behavior and corrections for mistakes. RLHF trains models using human feedback, making their responses more helpful and aligned with human values. This method helps models stay helpful and avoid harmful or biased answers.
Direct Preference Optimization (DPO)
It is a training method that helps AI models align with human preferences without using complex reinforcement learning processes. Traditional methods like Reinforcement Learning from Human Feedback (RLHF) require building a separate reward model to evaluate responses, followed by reinforcement learning to improve the model. This process can be slow and complicated.
In contrast, DPO simplifies this by directly using human feedback on pairs of responses to guide the model. It trains the model to generate answers that people prefer by optimizing a simple classification task—choosing better responses without needing a reward model. This makes DPO faster, more efficient, and more straightforward while still producing high-quality, human-aligned outputs.
Distillation:
Distillation transfers knowledge from a large pre-trained model (teacher) to a smaller model (student), allowing the student to deliver similar performance with lower inference costs in production.

Pruning:
Pruning reduces the size and complexity of large models by removing less important neurons or layers. Like trimming a tree to help it grow better, pruning makes models faster and more efficient without losing much accuracy. This process keeps only the most essential parts, making models easier to run on devices with limited resources.
Fine-tuning: Teaching LLMs
When we talk about fine-tuning in the LLM world, we're essentially teaching a smart model to become even smarter at specific tasks. While it might sound easy, the fine-tuning process requires high-quality training data, computational resources, and expertise to effectively train the model for its intended purpose.
The essential fine-tuning vocabulary and concepts in model fine-tuning:
Parameter-Efficient Fine-Tuning (PEFT): It is a technique that focuses on fine-tuning specific parts of the model, saving time and resources while achieving great results.
Parameters: The term "parameter" simply refers to settings or controls in different areas of AI. While we discussed Inference Parameters that control model outputs, here we're looking at Finetuning Parameters that control how models learn. Think of parameters as adjustable settings - like volume and brightness are parameters for a TV, AI has parameters for different functions like inference, training, and fine-tuning.
Below Terms are Finetuning Parameters:
Learning Rate: Speed at which model learns
Higher = Faster learning but may miss details
Lower = Careful learning but takes longer
Batch Size: Amount of training data processed at once
Larger = Faster training but needs more memory
Smaller = More accurate but slower training
Epochs: The number of times a model goes through the entire dataset during training.
More epochs: Model memorizes instead of learning. This leads to overfitting, think of a student who memorizes test answers but can't solve similar problems.
Fewer epochs: Model doesn't get enough time to learn patterns properly. This leads to underfitting - like a student who only reads chapter headings and misses the actual content, leading to poor performance on any type of question.
Warmup Steps: A short period at the start of training (like 500 or 1000 steps) where the learning starts gradually, allowing the model to ease into training and avoid big mistakes early on.
Weight Decay: A tiny number (like 0.01 or 0.0001) used to keep the model from becoming too confident and helps it work better with new data.
Dropout Rate: A percentage (like 20% or 50%) of model connections that are temporarily turned off during training, so the model doesn’t just memorize but actually learns.
Checkpoints: Saved snapshots of the training progress, similar to saving your progress in a video game. If something goes wrong, you can pick up where you left off instead of starting over.
Datasets: Collections of carefully chosen examples used to teach the model how to perform a specific task, like showing it lots of labeled pictures to learn image recognition.
Quantization: Converting model's high-precision numbers (32-bit) to lower precision (8-bit/4-bit) to make it smaller and faster. With quantization you lose some precision but gain efficiency.
Benchmarks: Standardized datasets and scoring methods used to measure how well a model performs.
MMLU (Massive Multitask Language Understanding): A set of multiple-choice questions across 57 subjects, testing how much general knowledge the model has.
HellaSwag: A dataset with 70,000 multiple-choice questions designed to test a model's common-sense reasoning in everyday scenarios.
SQUAD (Stanford Question Answering Dataset): Over 100,000 reading comprehension questions linked to Wikipedia passages, used to test how well the model answers questions based on text.
GLUE (General Language Understanding Evaluation): A collection of 9 different NLP (Natural Language Processing) tasks, each with its own dataset and evaluation metric, to test the model's overall language understanding.
Guardrails: Safety systems that ensure AI models behave appropriately. They filter harmful content, validate inputs, and control outputs. One can implement these safety checks wherever needed in their AI system. Example for guardrails include Anthropic's Constitutional AI, OpenAI’s Moderation API, NeMo-Guardrails, Guardrails AI.
RAG: Retrieval Augmented Generation:
Retrieval-Augmented Generation (RAG) is a technique that allows AI models to gain domain-specific knowledge by combining two steps:
Retrieval: The system pulls relevant information (like documents, personal notes, or reports) from a specific database or knowledge source.
Generation: The AI model uses the retrieved information, along with your input question, to generate a detailed and context-aware response.
While models come with broad knowledge from their training, they can't know your specific business data or particular domain information in detail. You can either fine-tune the model with your data, which requires significant computational resources, or use RAG as an alternative approach. RAG lets models access external information when needed instead of teaching everything through fine-tuning.
Key Terms of RAG:
Embedding: Domain data (docs, knowledge base) is converted into numerical vectors called embeddings that capture its meaning. We have embedding models available to perform this task.
Example: NV-Embed-v2, bge-en-icl
Vector Database: A database that stores embeddings (numerical representations) of documents and domain knowledge, making them searchable. When a query comes in, it helps find the most relevant information.
Example: PostgreSQL, Pinecone, Qdrant
Indexing: A method used by the vector database to organize embeddings, ensuring fast and efficient retrieval during the RAG process.
Semantic Search: A search method that matches content based on meaning, not just keywords. This helps find relevant information even when the exact words don’t align.
Hybrid Search: Semantic Search + Keyword Search
Retrieval: The process of identifying and retrieving the most relevant documents by matching embeddings to the query. These documents provide the necessary context for the AI model’s response.
Re-ranking: After retrieving multiple documents, this step prioritizes them based on relevance, ensuring the most useful information is used for the response.
Cosine Similarity: A mathematical measure used to determine the similarity between two embeddings, helping to rank retrieved documents by relevance.
Each of these components works together in the LLM ecosystem, creating a powerful system that can think, communicate, and access information effectively.
Function/Tool Calling:
Heard of function or tool calling? It’s widely used in AI Agents.
Function or Tool calling is basically how AI models can interact with different tools and services.
In LangChain, this capability is implemented through a structured system.
The process involves:
Tool Creation: Defining functions with clear inputs and outputs
Tool Binding: Connecting these tools to the AI model
Tool Calling: The model deciding when and how to use these tools
Tool Execution: Actually, running the function with the right parameters
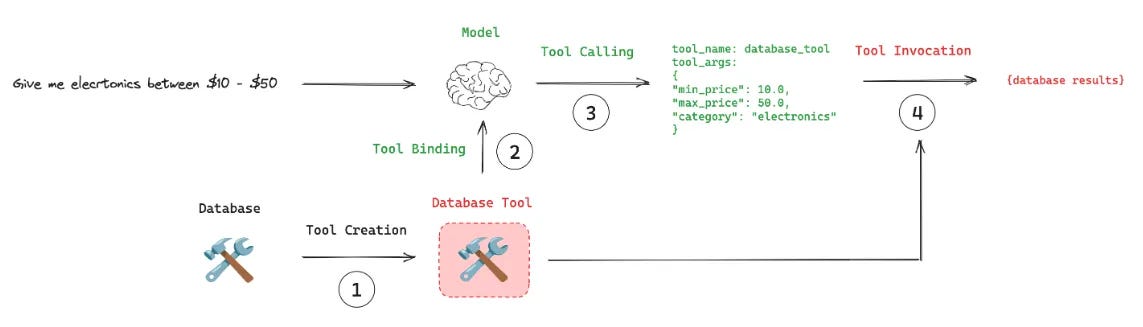
In simpler terms, it's what turns a regular chatbot into a capable assistant that can get things done.
LLM Frameworks:
LLM frameworks like LangChain and LlamaIndex simplify AI development by providing ready-to-use components. They handle model integration, data connections, and common workflows, making it easier to build practical AI applications.
What’s Next?
In this post, we explored the essential LLM terms and concepts. Whether you're building AI applications, fine-tuning models, or just exploring AI, these fundamentals will set you up for the journey ahead.
While we've covered the most commonly used LLM terms, we haven't yet explored concepts related to Agents and the deeper aspects of RAG. We plan to cover more of that in the future posts.
Stay tuned! Happy Learning!
A great summary, thank you!