
How to use Postgres as a Vector Database with BGE Embedding model
A Developer’s Guide for using PostgreSQL as a Vector Database with BGE Embeddings for Efficient Retrieval


Vector databases have become increasingly popular, with many articles exploring PostgreSQL's capabilities in this domain. This guide takes a different approach by integrating the BGE Embedding model for generating embeddings, along with storage and retrieval processes in Postgres.
For those new to vector databases, Postgres with PG Vector offers efficient storage, indexing, and querying of vector data, ideal for similarity search and document retrieval. We'll cover setting up Postgres with PG Vector, generating BGE embeddings, and performing quick similarity searches.
Let's dive into the topics:
Embeddings Explained
Introduction to BGE Model
Why do we need to store embeddings?
Why Postgres - PG Vector?
Postgres, PG Vector, Installation and Setup
Embedding Generation, Storage, and Retrieval with PostgreSQL
Summary and Insights
The diagram below provides a complete summary of the entire blog

Embeddings Explained
Embeddings are dense vector representations that capture the semantic meaning of text, images, or videos. They are generated by models trained on large datasets. Embeddings capture detailed relationships and contexts. This enables the measurement and comparison of how closely related different pieces of information are.

While dense vectors are commonly used for embeddings due to their ability to represent complex semantic relationships, it's important to understand that there are also sparse vector representations in NLP. The choice between dense and sparse vectors can significantly impact how information is represented and processed, as discussed in the comparison below.
What is Dense & Sparse Vectors?

Best uses:
Dense vectors: Ideal for capturing nuanced meanings in language, where subtle differences between words or phrases are important.
Sparse vectors: Efficient for straightforward text analysis tasks, involving large vocabularies, where each document uses only a small portion of the overall vocabulary.
Why Embedding?
Embeddings are essential for tasks that require understanding relationships between pieces of information. They power various applications.
Search Engines: Find relevant documents (e.g., "best Italian restaurants near me")
Recommendation Systems: Suggest similar content (e.g., mystery thrillers with plot twists)
Text Classification: Categorize messages (e.g., identifying spam emails)
Document Clustering: Group-related articles (e.g., on renewable energy policies)
Sentiment Analysis: Determine text tone (e.g., positive product reviews)
How do embeddings be used to find relevant documents?
The Embedding Model transforms sentences into vector representations, capturing their semantic meaning. Consider these four sentences, with their embeddings.
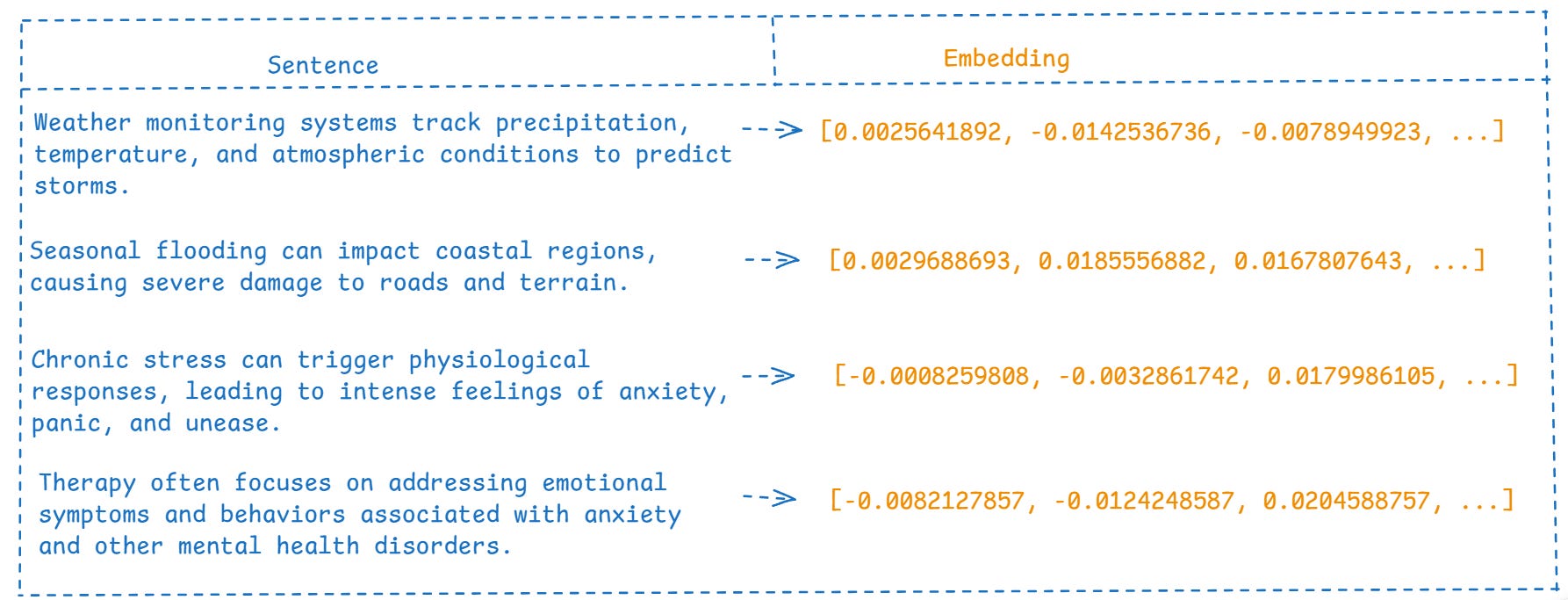
When we plot embeddings in multidimensional space, keywords from semantically related sentences cluster together.
Weather-related grouping: Words from the first sentence like "weather," "precipitation," and "temperature" are near terms from the second sentence such as "flooding," "coastal," and "terrain" in the embedding space. This proximity allows the model to recognize these sentences as semantically related, even though they discuss different aspects of weather and its effects.
Anxiety-related grouping: Similarly, "stress" and "anxiety" from the third sentence appear close to "emotional" and "mental health" from the fourth sentence in the embedding plot. This enables the model to identify that both sentences are related to psychological well-being, despite focusing on different aspects (causes vs. treatment).
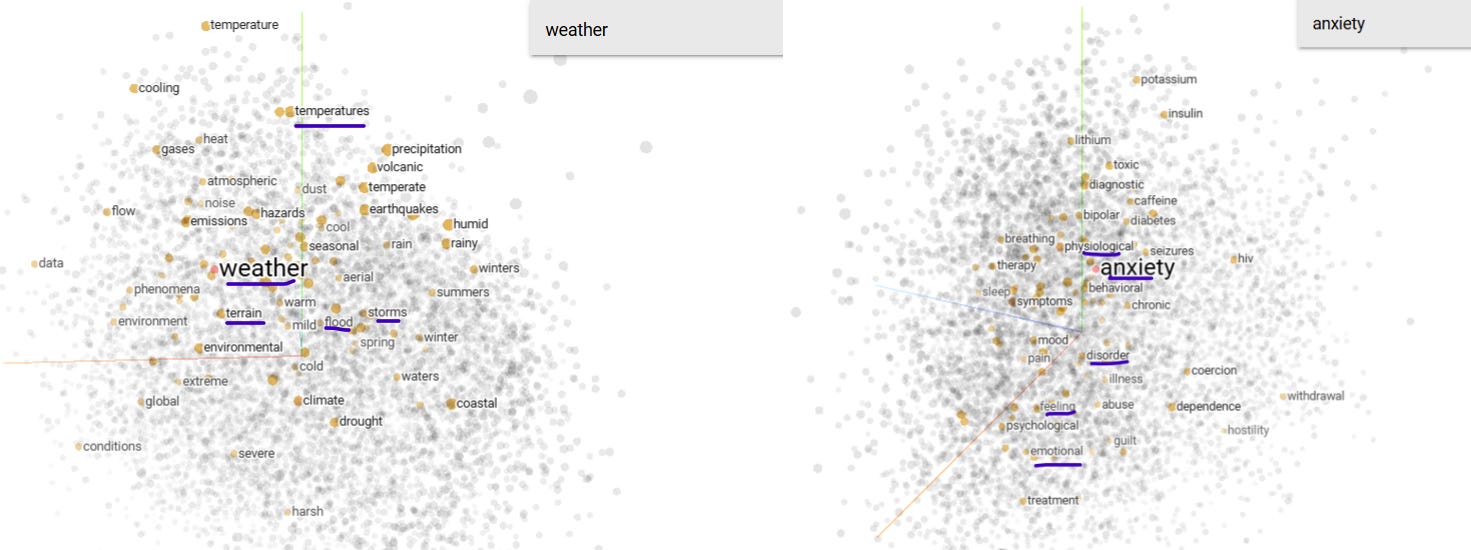
This word-level proximity in the embedding space is key to how the model or we group semantically similar sentences, capturing relationships beyond exact word matches. Similar sentences are now grouped.

Introduction to BGE Model:
BGE (BAAI general embedding) is an open-source series from the Beijing Academy of Artificial Intelligence, specializing in mapping text to low-dimensional dense vectors.
The BGE model is recognized as one of the top-performing models on the MTEB Leaderboard. They can be utilized through Flag Embedding, Sentence-Transformers, LangChain, or Huggingface Transformers. BGE is available in different sizes (e.g., large, base), you can refer to this page for the available models.
Let's analyze two closely related phrases: "Heavy Rain" and "Heavy Flood." By calculating their similarity score through embeddings, we can determine how closely these sentences are represented in vector space, reflecting our natural understanding of their relationship. Here’s how you can convert a sentence to embeddings using the BGE model through Flag Embedding.
# Import packages
from FlagEmbedding import FlagModel
# Define the two sentences for which we want to calculate the similarity
sentence_1 = ["Heavy Flood"]
sentence_2 = ["Heavy Rain"]
# Initialize the BGE (Bi-Gram Embedding) model from BAAI, using fp16 precision for faster computation
model = FlagModel('BAAI/bge-base-en-v1.5', use_fp16=True)
# Encode the first sentence to generate its vector embedding
embeddings_1 = model.encode(sentence_1)
# Encode the second sentence to generate its vector embedding
embeddings_2 = model.encode(sentence_2)
# Print out the embeddings (vector representation) of the first and second sentence
print("Embedding for sentence_1: ", embeddings_1)
print("Embedding for sentence_2: ", embeddings_2)
# Calculate the cosine similarity between the two embeddings by taking their dot product (matrix multiplication)
similarity = embeddings_1 @ embeddings_2.T # @ is shorthand for matrix multiplication
# Print the similarity score, which indicates how close or semantically similar the two sentences are
print("Similarity score between sentence_1 and sentence_2: ", similarity)Curious to see the similarity score between sentence_1 = ["Heavy Flood"] and sentence_2 = ["Heavy Rain"]? See below.
Embedding for sentence_1: [[-0.00287752 0.04383265 -0.01180796 ... -0.02703355 0.05103137 0.01539739]]
Embedding for statement 2: [[-0.00076429 0.05304793 -0.02597153 ... -0.03111602 0.00311398 0.00415416]]
Similarity score between sentence_1 and sentence_2: [[0.741174]Cosine similarity scores range from -1 to 1, where -1 indicates complete dissimilarity, 0 represents no similarity, and 1 shows perfect similarity. A score of 0.741174 suggests strong semantic alignment between the query and retrieved documents, highlighting the effectiveness of the embedding model and similarity search in capturing conceptual meaning beyond just keywords.

Got it? Here comes the next question.
Why do we need to store embeddings?
When finding the most relevant sentence for a new query, you first compute the query's embedding, which is a numerical representation of the query. Then, you compare this embedding to those of existing sentences to identify the one with the highest similarity score. This approach works well with small datasets but becomes impractical with larger ones.
The main challenges are the high computational overhead of generating embeddings for a large number of sentences in real-time and the inefficiency of repeatedly computing the same embeddings, which slows down response times.
To address these issues, we store pre-computed embeddings in a database. This strategy allows for faster retrieval of embeddings, reduces the computational load during queries, and makes similarity comparisons more efficient.
Why Postgres- PG Vector?
Although standalone vector databases offer specialized functionality, they often introduce hidden complexities, especially when integrating with existing data infrastructures. PGVector, as an extension of PostgreSQL, addresses these challenges by incorporating vector search capabilities into a mature, full-featured database system. This approach eliminates the need for complex data synchronization, provides metadata storage, and leverages PostgreSQL's robust security and scaling features.

As this comparison highlights PGVector's advantages over standalone databases, here is one real-time article that demonstrates why they made the switch to PGVector.
Postgres, PG Vector, Installation, and Setup:
Download and install PostgreSQL by selecting the appropriate installer for your operating system: - PostgreSQL: Downloads
Once Postgres is installed, now install PG Vector Extension (Note: The following steps are for Windows. For other operating systems, please refer to the instructions here.)
Note 1:- Make sure [C++ support in Visual Studio](<https://learn.microsoft.com/en-us/cpp/build/building-on-the-command-line?view=msvc-170#download-and-install-the-tools>) is installed.
Note 2:- Ensure to set Postgres path “C:\Program Files\PostgreSQL\16” in the PATH env variable.
Open VSCode Terminal and run the below commands:
call "C:\Program Files\Microsoft Visual Studio\2022\Community\VC\Auxiliary\Build\vcvars64.bat"
set "PGROOT=C:\Program Files\PostgreSQL\16"
cd %TEMP%
git clone --branch v0.7.4 https://github.com/pgvector/pgvector.git
cd pgvector
nmake /F Makefile.win
nmake /F Makefile.win installEmbedding Generation, Storage, and Retrieval with PostgreSQL
After setting up Postgres and PG Vector, you'll need to activate the extension (this must be done once for each database where you intend to use it).
CREATE EXTENSION vector;Once you've completed the setup, you can run the program below to generate embeddings and handle their storage and retrieval from PostgreSQL.
Note: Attention to the explicit type cast to vector in the SQL query. Without it, you may encounter an error like: "Error executing query: operator does not exist: vector <#> numeric[]."
import psycopg2
from FlagEmbedding import FlagModel
# Initialize the BGE model
model = FlagModel('BAAI/bge-base-en-v1.5', use_fp16=True)
def generate_embeddings(text):
if isinstance(text, str):
text = [text]
embeddings = model.encode(text)
if len(embeddings) == 1:
return embeddings[0].tolist()
return embeddings.tolist()
def run():
conn = psycopg2.connect(
user="postgres", # postgres username given during the installation
password="postgres", # postgres password given during the installation
host="localhost",
port=5432,
database="vectordb"
)
cur = conn.cursor()
try:
# Ensure the necessary extension and table are created
cur.execute("CREATE EXTENSION IF NOT EXISTS vector")
cur.execute("""
CREATE TABLE IF NOT EXISTS sentences (
id SERIAL PRIMARY KEY,
sentence TEXT,
embedding vector(1024)
)
""")
sentences = [
"AI-driven digital polygraphs are gaining popularity for real-time deception analysis, offering a new frontier in risk assessment.",
"Amazon's newly launched AI tool can generate product listings, revolutionizing how sellers create content for their products.",
"AI-generated short films have become a marketing trend, with brands like KFC using them to capture audience attention.",
"Instacart has introduced smart shopping trolleys powered by AI, aiming to enhance customer experience in retail.",
"AI tools are being used to generate custom tattoo designs from simple text prompts, allowing users to personalize their ink dreams.",
"IBM's AI is enhancing the 2024 US Open, providing more in-depth player analysis and improving the fan experience."]
# Insert sentences into the sentences table
for sentence in sentences:
embedding = generate_embeddings(sentence)
cur.execute(
"INSERT INTO sentences (sentence, embedding) VALUES (%s, %s)",
(sentence, embedding)
)
# Commit the insertions
conn.commit()
# Example query
query = "What AI tools are being used by e-commerce companies like Amazon for product listings and customer engagement?"
query_embedding = generate_embeddings(query)
# Perform a cosine similarity search using dot product and magnitude
# Note the explicit type cast to vector in the SQL query
cur.execute(
"""
SELECT id, sentence,
1 - (embedding <=> %s::vector) AS cosine_similarity
FROM sentences
ORDER BY cosine_similarity DESC
LIMIT 5
""",
(query_embedding,)
)
# Fetch and print the result
print("Query:", query)
print("Most relevant sentences:")
for row in cur.fetchall():
print(f"ID: {row[0]}, SENTENCE: {row[1]}, Cosine Similarity: {row[2]}")
except Exception as e:
print("Error executing query", str(e))
finally:
cur.close()
conn.close()
if __name__ == "__main__":
run()The output of the above program appears as follows:
Do you see how the relevant sentence is retrieved from the set of sentences with embeddings that we stored?
Query: What AI tools are being used by e-commerce companies like Amazon for product listings and customer engagement?
Most relevant sentences:
ID: 32, SENTENCE: Amazon's newly launched AI tool can generate product listings, revolutionizing how sellers create content for their products., Cosine Similarity: 0.8105140441349733The structure of our VectorDB table, which stores embeddings, is illustrated below. This table consists of three columns: 'id' (an integer primary key), 'sentence' (text content), and 'embedding' (vector representation). Each row represents a unique entry, pairing a sentence with its corresponding embedding vector.

Summary
BGE models are the best open-source models for creating embeddings, that work with PostgreSQL's PG Vector extension. Together with your chosen LLM, this forms a complete stack for building AI applications.
Further Reading
Want to explore more? Here's how to dive deeper:
With these tools and your preferred LLM, you're all set to build your own RAG applications. Happy coding!