

I attended an AI conference where teams from big companies shared how they moved their agentic apps to production. The talks were full of real lessons from people who’ve built and deployed agentic systems in production.
When you build an agent, the demo usually looks smooth. But once you run it in production, new challenges appear around safety, memory, recovery, and control.
The conference focused on what we need to consider before moving agentic apps to production. Below are the five areas that were discussed the most. That’s exactly what we’ll cover in this blog.
Guardrails
Memory Management
Error Handling and Recovery
Human in the Loop
Observability and Monitoring
If you are moving your agentic app to production, make sure you can confidently say yes to these questions.

1. Guardrails
If you ask an AI chatbot for something harmful, it will refuse. That is a guardrail which keeps the system safe, ethical, and within limits.
Guardrails act as a shield for agentic apps. They protect the agent from bad inputs and make sure it responds in the right way. In simple terms it defines the boundaries for an agent’s behavior. They keep it safe, prevent unwanted actions, and ensure it only operates within its intended scope.
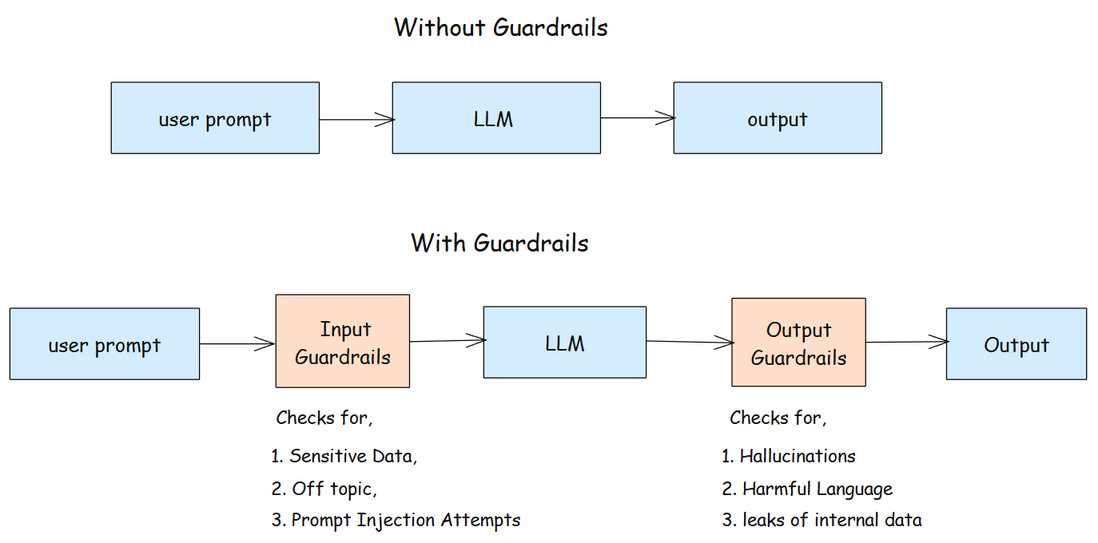
Why Guardrails
In real-world setups, guardrails don’t stop at inputs and outputs. They extend across multiple layers to control how agents act, decide, and interact with tools or users. Each layer adds safety and stability to the system.
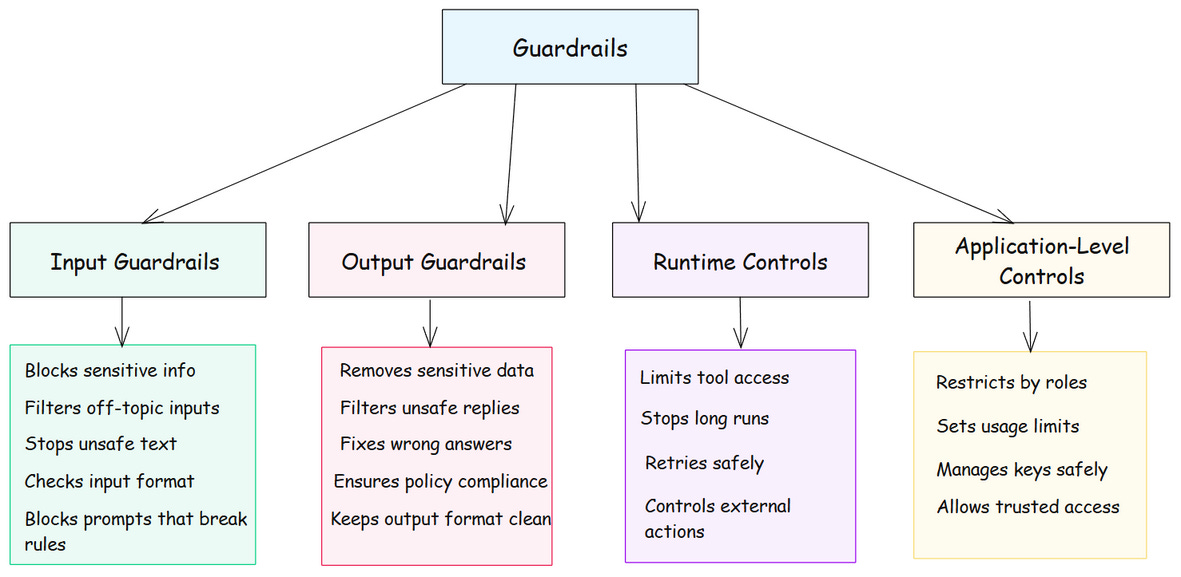
Tools and Frameworks for Guardrails
There are two main ways to add guardrails when taking an agentic system to production.
You can use the built-in guardrails that come with your agent framework or integrate separate libraries for more control and compliance.
Frameworks like LangGraph and OpenAI Agent SDK already include basic checks such as input moderation, safe tool access, and retry logic. For most apps, these are enough.
If you need deeper validation, you can plug in external toolkits built for strong control.
Guardrails AI is a Python framework. It helps build reliable and safe AI applications. It works by adding input and output “guards” around your LLM calls. These guards detect and reduce different types of risks in real time, such as toxic language, personal data leaks or exposed secrets.
NVIDIA NeMo Guardrails is an open-source toolkit by NVIDIA. It lets you add programmable guardrails to your AI Apps. It works by layering “rails” between your application logic and the LLM. It controls how the model behaves, what it says, and what actions it takes.
Microsoft Presidio is an open-source framework. It focuses on detecting and redacting personal or sensitive data (PII) in text and images. It has options for connecting to external PII detection models.
Langchain Guardrails provide built in guardrails. They can detect sensitive information, enforce policies, validate outputs, and prevent unsafe behaviors before they cause problems.
OpenAI Agents SDK includes built-in guardrails for both inputs and outputs. These run alongside your agents to validate and enforce safe behavior in agentic apps.
OpenAI Guardrails is a ready-to-use toolkit for adding safety and compliance checks to your LLM apps. You can select prebuilt guardrails such as Mask PII, Moderation API, or Jailbreak Detection directly from the dashboard, export them as a JSON config file, and use them in your application.
You can also build your own guardrails for your app. Think of them as simple toolkits that protect your agentic system and keep it under control.
2. Memory Management
When you chat with ChatGPT, it remembers what you said earlier. That is what memory does. It helps the system stay consistent and feel more human.
Memory helps the agent retain context, recall past steps so it can respond properly.
An agent without memory starts from zero every time. With memory, it remembers what happened, adapts to the user, and gets smarter with every run.
The Redis blog explains this well. Here’s how short-term and long-term memory connect with the agent, tools, and LLM.

Types of Memory
Agents work with two types of memory.
Short-term memory – Keeps track of recent steps or the current task.
Long-term memory – Holds information that should last beyond a single run. This could be user details, preferences, or past interactions.
Different frameworks handle memory in their own ways.
In LangGraph, every message is saved in the state variable as an AIMessage or HumanMessage. This helps the agent maintain context during the current session. When the agent restarts, it starts fresh. That’s short-term memory.
To make it remember across sessions, you need long-term memory. Here, past messages or summaries are stored externally, usually in a vector database or memory store. This allows the agent to retrieve relevant context from older sessions when needed.
The LangChain video explains this Agent memory well.
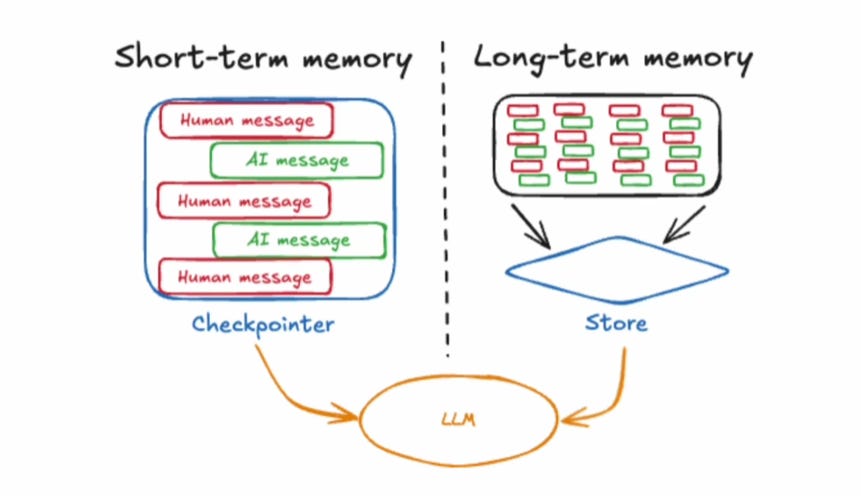
Why Memory Matters
Most LLMs are stateless. They don’t remember what happened earlier unless we tell them. In real-world apps, that’s not enough.
Agents need memory to recall user preferences, track progress, and carry context across steps. Without it, they repeat questions and lose continuity.
Without good memory design, too much context slows down responses, increases cost, and can even confuse the model.
Tools and Frameworks for Memory
When you’re building agentic apps, you don’t have to invent your memory layer from scratch. There are tools and frameworks ready for use.
Mem0: A self-improving memory layer for AI agents that stores user preferences and past sessions. It supports short- and long-term memory.
Graphiti: An open-source Python framework for building temporally aware knowledge graphs for agents. It captures relationships over time, enabling agents to reason beyond vector store.
Zep: Zep is a memory platform for AI agents. It learns from user interactions. It builds a time-based knowledge graph that helps agents give accurate and personalized answers. Over time, it keeps learning and improving user experience. It is powered by Graphiti.
3. Error Handling and Recovery
When you run agentic apps in production, things will break. A tool call might fail, an API might timeout, or the model might return something you didn’t expect. Error handling and recovery is about catching those issues, dealing with them properly, and keeping the agent running safely.
Why It Matters
Agentic apps rarely fail because of big bugs. They fail because of the small things like a bad response, or a tool call that never returns. One silent error can stop the whole workflow. Without a plan, the agent either crashes or keeps looping endlessly trying to fix itself.
Good error handling makes your agent resilient. It helps the agent fail safely and continue from where it left off.
How to Handle Errors in Production
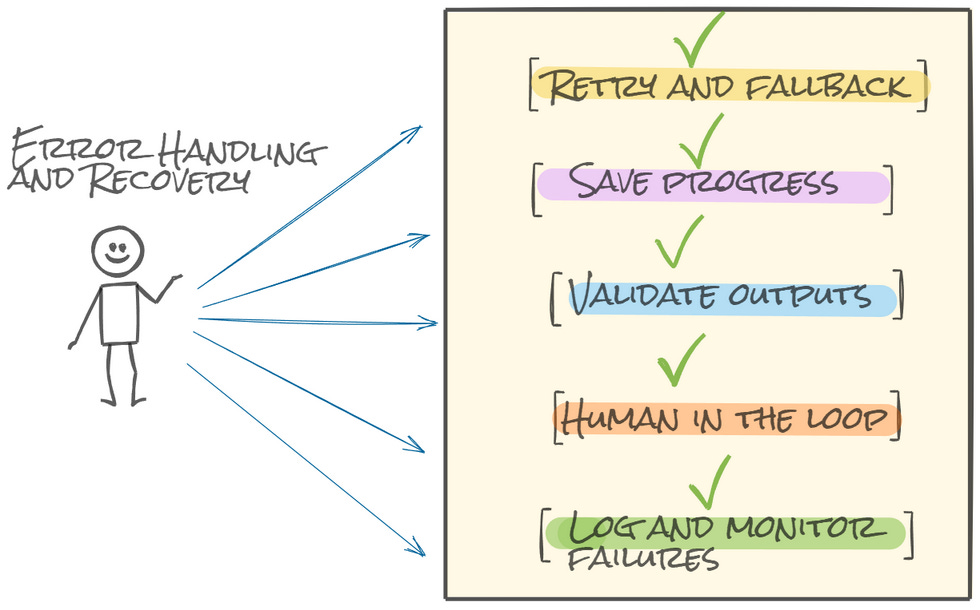
Retry and fallback - Add retry logic for every tool or API call and have a fallback plan when retries fail.
Save progress - Use checkpoints to save the agent’s state so it can resume after failure.
Validate outputs - Always check if the model’s response or tool output is valid before using it.
Add a human step when needed - Some errors need manual review. Don’t let the agent keep guessing.
Log and monitor failures - Track the errors. This helps you fix recurring issues early.
4. Human in the Loop (HITL)
Human in the Loop (HITL) adds a human step inside the agent’s workflow. The agent pauses, waits for human input or approval, and then continues. It keeps humans involved at key moments and lets them guide the agent when needed.
Why It Matters
Agents can automate a lot, but not everything should run on autopilot. When a task involves compliance, sensitive data, or critical actions, a human check adds safety. It keeps the system reliable.
How to Add HITL in Production
Many frameworks support adding human-in-the-loop steps directly into your workflows.
You can add a LangGraph Human in the Loop step using the
interrupt()function inside a node. The agent stops, waits for feedback, and then continues from the same point. This is useful when the agent needs human confirmation before taking an action.CrewAI supports human-input tasks within the workflow. You can enable this by setting
human_input=Truein the task configuration. When the agent reaches that task, it pauses, collects feedback, and moves forward with the updated response.In OpenAI’s Agents SDK, you can mark certain actions for approval using
needsApproval=True. The agent pauses at those steps until the user reviews and confirms, keeping humans involved in key decisions.Google’s ADK supports a human-in-the-Loop pattern. You can create a small review agent that asks for user confirmation before the main agent continues. This keeps humans in control of important decisions.
5. Observability and Monitoring
Almost every team at the conference talked about this part. No matter how advanced their setup was, observability came up again and again.
Observability shows how your agent really works, not just what it outputs. It helps you follow every step the model takes, from the first prompt to the final response.
In real-world agentic systems where many tools, memory calls, and APIs run together, observability becomes essential. It helps you spot failures early, understand the cause, and measure how each part performs.
Langfuse for Observability and Monitoring
Langfuse is an open-source observability tool built for LLM and agentic applications. It records each step in the workflow and shows a full trace of what happened. You can see how prompts evolved, which tools were called, what data was fetched, and how long each step took.
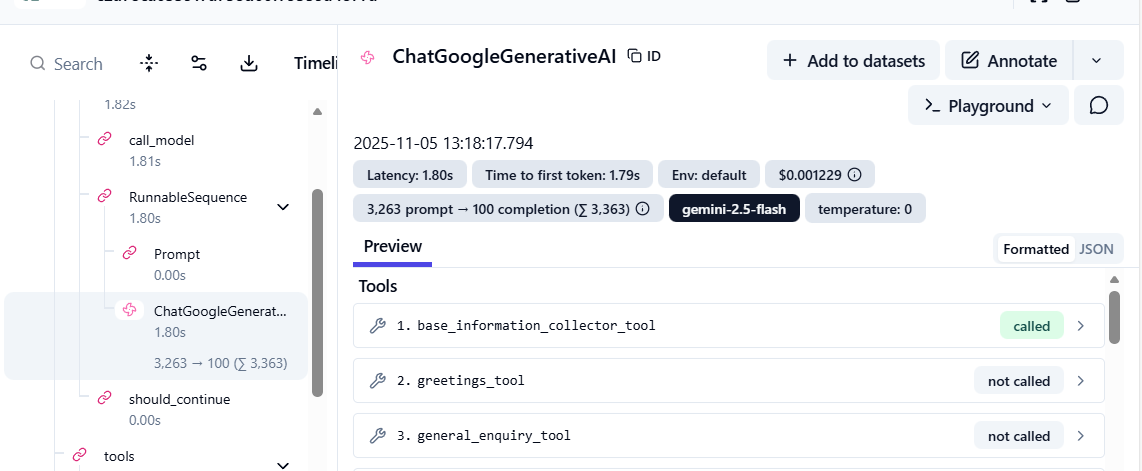
I integrated Langfuse into one of my agentic apps to see what kind of traces it captures and how deep the visibility goes.
I was able to capture all traces and observations from the app in one place. I could see the total traces, token usage, and model cost for my app at a glance.
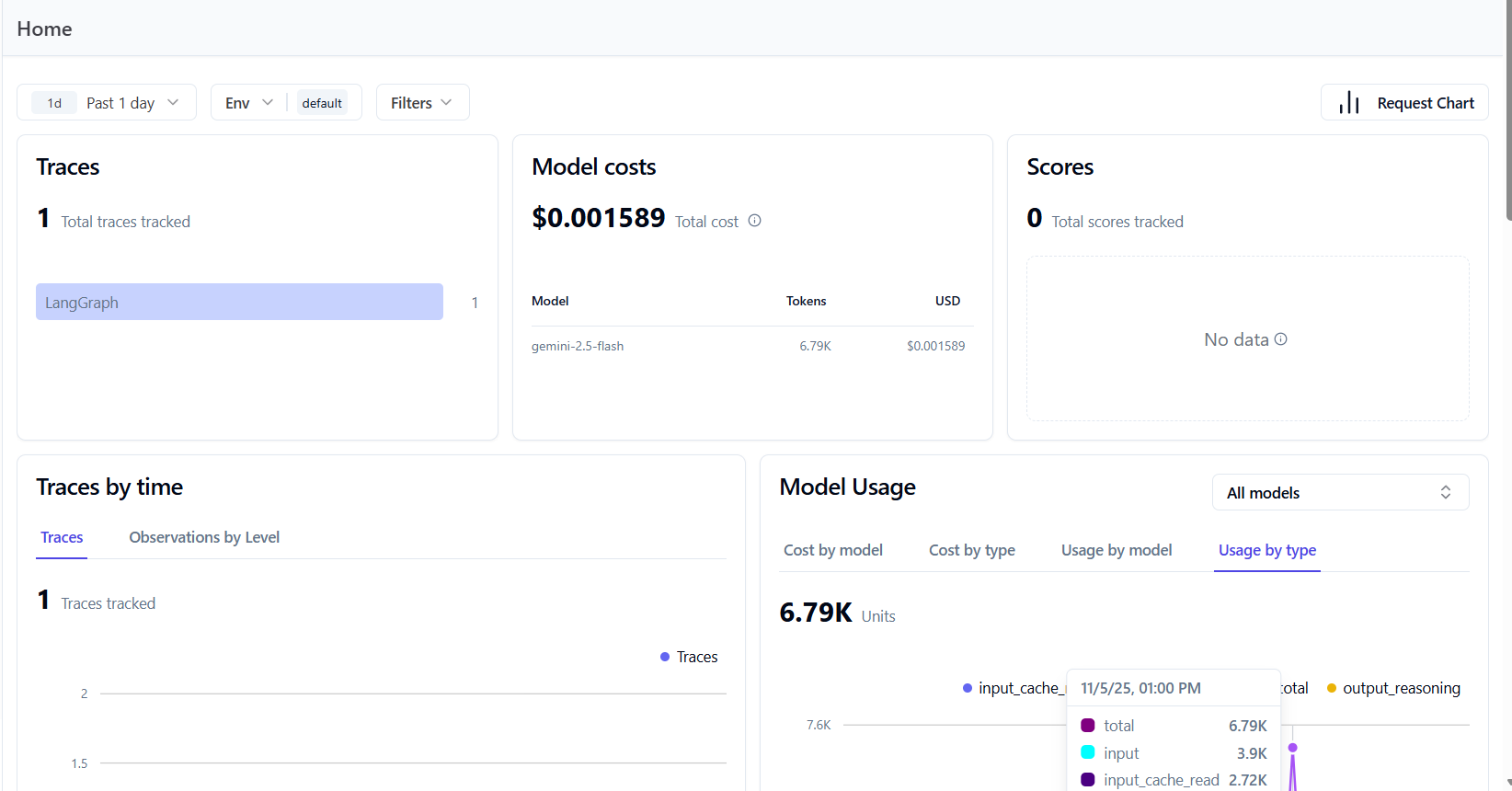
This view gave me a full snapshot of each run - inputs, outputs, and all the metadata in between.
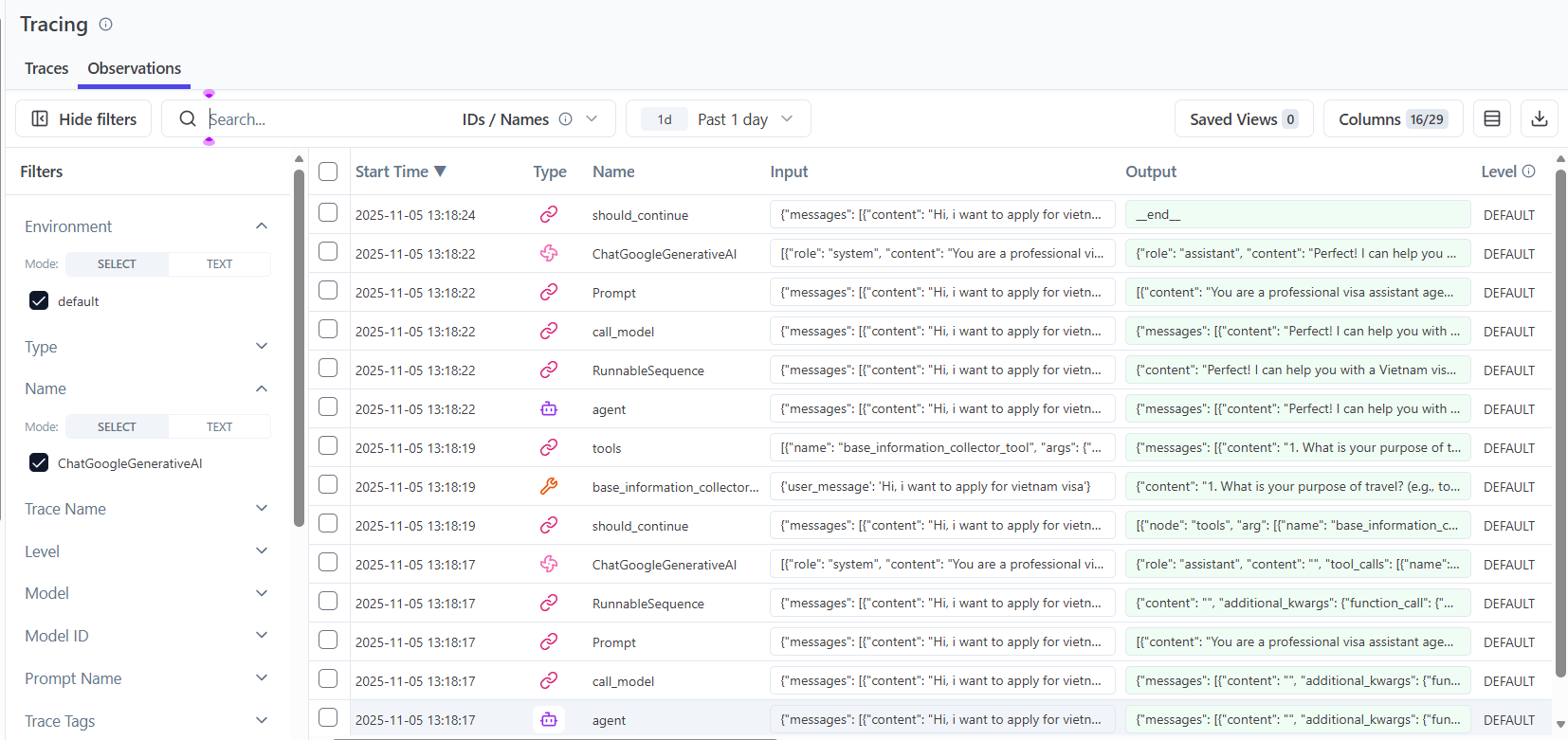
When I opened a single trace, I could see the full flow, how the user’s input moved through each tool and LLM call, step by step. Both preview and raw JSON views made it clear what data was being passed across the system.
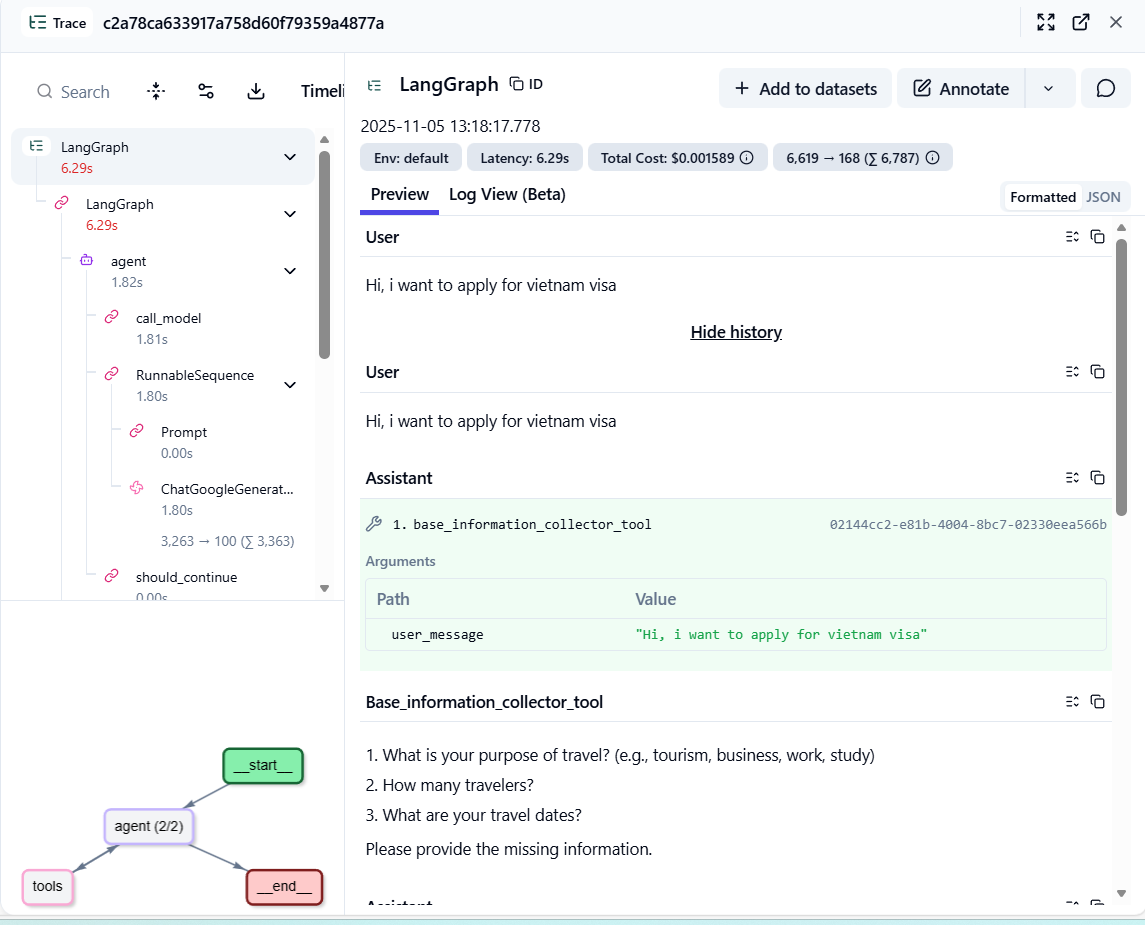
It also captured detailed tool-level metrics. Langfuse showed which tools were triggered, how long they took, and how much each call cost. It’s a simple way to track efficiency and debug issues without digging through logs.
Conclusion
Taking agentic apps to production needs more than just good prompts or models.
They need safety, memory, recovery, human checks, and visibility.
Guardrails keep your agents safe.
Memory helps them stay consistent.
Error handling makes them reliable.
Human-in-the-loop brings control.
Observability shows how everything works together.
Build, test, observe, and refine. That’s how good agents become production ready.
Hope you find this blog useful!
Happy Building!