

We have been talking about AI agents for a while. This week’s blog is again about agents. But this time, it’s about voice agents. The recent announcement of “Sonic 3 - the state of the art model in conversation” made me curious to explore voice agents. Let us see how far we have come in this space.
During the LLM wave, we saw models that could convert text to speech. Now, in the agent era, voice agents are taking the spotlight. Out of every ten calls I get, at least one is from an automated voice agent promoting something. The conversational AI space is growing fast.
So, let’s explore how to build our own voice agent.
In this blog, we will cover,
Getting Started with Voice Agents
Frameworks for Voice Agents
Building voice agents with code -OpenAI’s Agent SDK
Building voice agents without code - Voice Flow, Retell AI, Vapi
Further Reading: TTS, STT, and Speech-to-Speech Models and APIs
1. Getting Started with Voice Agents
We have come a long way from simple text-to-speech models. Voice agents today can talk, reason, and respond in real time. It’s a big step forward in conversational AI.
A voice agent is a virtual assistant that holds natural conversations. It works over phone calls or websites. The agent listens to speech, processes it using language models, takes action, and responds in a human-like voice.
These agents can handle real tasks. They schedule appointments, answer customer questions, and make sales calls. They can call APIs, maintain context across conversations, and connect with other systems to get things done.
You can build voice agents in two ways.
Pipeline Method
The first way is a kind of pipeline approach using separate models:
Speech-to-text (STT)
A language model for reasoning and tool calls,
Text-to-speech. (TTS)
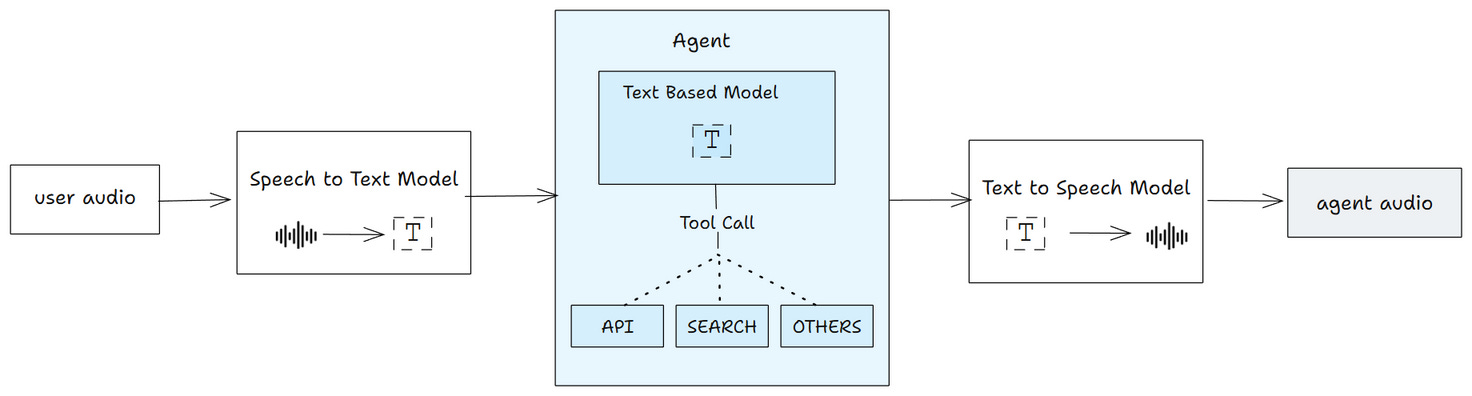
Example speech-to-text models: Whisper, Deepgram, AssemblyAI
Example text-to-speech models: gpt-4o-mini-tts, Google TTS, ElevenLabs, Sonic 3
Speech to Speech Method
The second approach uses a single speech-to-speech model. This removes the hand-off delays between STT and TTS models, making conversations smoother. This is faster and feels more natural.
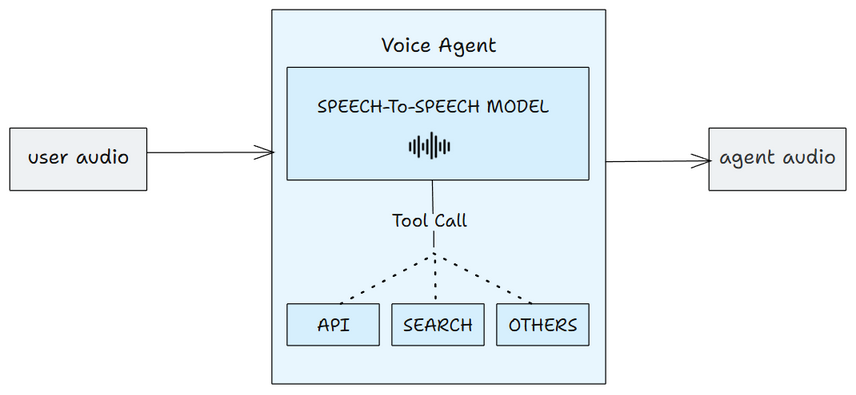
Example speech-to-speech models: GPT Realtime Models, Gemini Models ,
Now that you understand how voice agents work, here’s how to choose the right approach for your project.
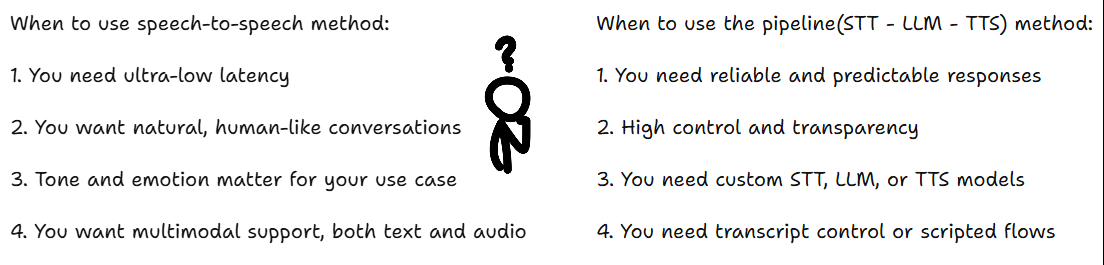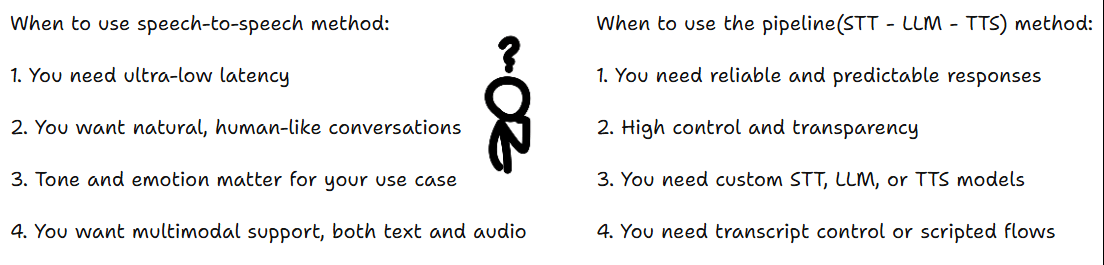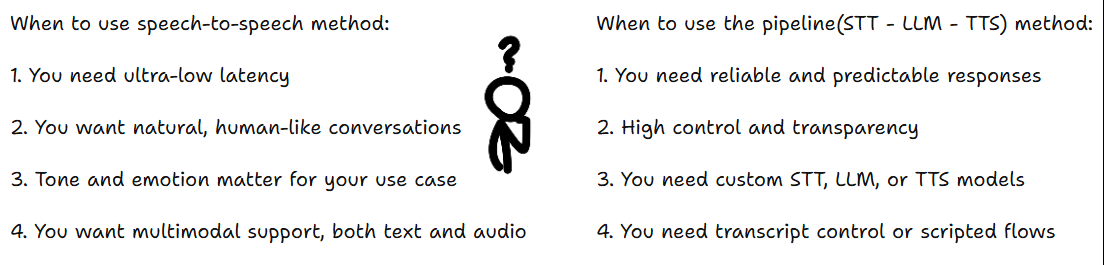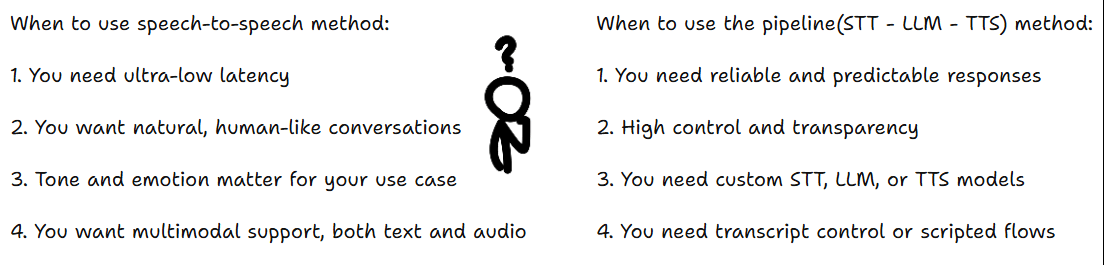
2. Frameworks for Voice Agents
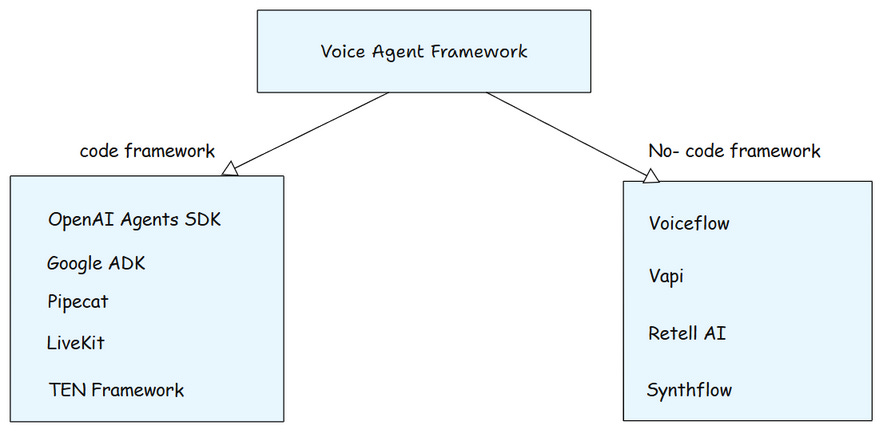
As voice agents become more common, new frameworks are coming up to build and launch them faster.
Like other AI agents, voice agents also have two types of frameworks - code and no code.
Code frameworks give developers full control. They let you handle speech, logic, and real-time audio in your own way.
No code frameworks help teams move faster. You can design, test, and launch voice agents with visual tools.
3. Building Voice Agents with code - OpenAI’s Agent SDK
Let us first build a simple voice agent using OpenAI Agent SDK.
This voice agent can search for files on your laptop. You can ask it to find files by name in specific folders like Downloads, Documents, or Desktop. Just speak naturally, and it will search and tell you what it found.
How it works
This voice agent follows a five-step process from input to output.
Sound Device - This Python library captures audio from your microphone.
Voice Pipeline - It converts your speech into text using a speech-to-text model.
Agent SDK - The agent reads the text, executes the logic, and generates a response.
Voice Pipeline - It converts the agent’s text response back into natural voice audio.
Sound Device - The library plays the voice response through your speakers.
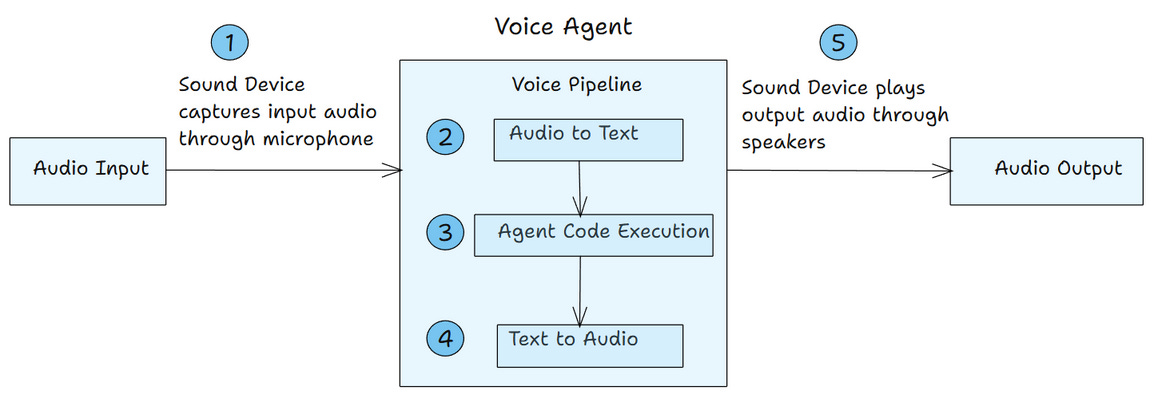
The entire flow happens in real time. You speak, the agent processes, and responds with voice.
Here is the code
1. Install required packages
pip install openai-agents[voice] sounddevice scipy 2. Setting Up the File Search Tool
import asyncio
import os
import sounddevice as sd
from scipy.io import wavfile
from agents import Agent, function_tool
from agents.voice import AudioInput, SingleAgentVoiceWorkflow, VoicePipeline
@function_tool
def search_files(pattern: str, directory: str = “home”) -> str:
“”“Search for files matching a pattern in common directories.”“”
import glob
BASE_DIR = r”C:\Users\YourUsername” # Change this
# Map common folder names
folder_map = {
“downloads”: “Downloads”, “documents”: “Documents”,
“desktop”: “Desktop”, “pictures”: “Pictures”, “home”: “”
}
# Determine search directory
dir_lower = directory.lower().strip()
if dir_lower in folder_map:
folder_name = folder_map[dir_lower]
search_dir = os.path.join(BASE_DIR, folder_name) if folder_name else BASE_DIR
else:
search_dir = directory
# Search for files
files = glob.glob(f”{search_dir}/**/*{pattern}*”, recursive=True)[:10]
if not files:
return f”No files found matching ‘{pattern}’”
result = f”Found {len(files)} file(s):\n”
for f in files:
result += f”- {f}\n”
return result3. Creating the Agent with tool access
agent = Agent(
name=”FileSearchAssistant”,
instructions=”You help users search for files. Be concise.”,
model=”gpt-4.1”,
tools=[search_files],
)4. Capturing User Audio
def record_audio(duration=8, samplerate=24000):
“”“Record audio from microphone.”“”
print(f”Recording for {duration} seconds... Speak now!”)
recording = sd.rec(int(duration * samplerate), samplerate=samplerate,
channels=1, dtype=np.int16)
sd.wait()
wavfile.write(”user_input.wav”, samplerate, recording)
return recording.flatten()5. Processing Audio Through Pipeline
async def process_voice():
# Capture voice
audio_data = record_audio(duration=8)
# Create pipeline and process
pipeline = VoicePipeline(workflow=SingleAgentVoiceWorkflow(agent))
audio_input = AudioInput(buffer=audio_data)
result = await pipeline.run(audio_input)
return result6. Playing Agent Response
async def main():
print(”Voice Agent - File Search”)
# Process voice through pipeline
result = await process_voice()
# Play response
print(”Playing response...”)
player = sd.OutputStream(samplerate=24000, channels=1, dtype=np.int16)
player.start()
output_audio = []
async for event in result.stream():
if event.type == “voice_stream_event_audio”:
player.write(event.data)
output_audio.append(event.data)
player.stop()
# Save output
if output_audio:
agent_audio = np.concatenate(output_audio)
wavfile.write(”agent_output.wav”, 24000, agent_audio)
print(”Done!”)
if __name__ == “__main__”:
asyncio.run(main())To run:
python voice_agent.pyBelow is an example conversation
I asked: “Search for MCP text file in the Applications folder”
Listen to my voice input
The agent searched through my Applications directory and found matching files.
Listen to agent’s response
Choosing Your Transport Method
Latency matters in voice agents. OpenAI’s Realtime API offers two low-latency transport methods.
1. WebRTC (Client-side)
Best for browser-based voice agents.
Peer-to-peer connection with low latency.
Direct audio streaming between user and OpenAI.
2. WebSocket (Server-side)
Best for phone call systems.
More control over the call flow.
Required integrations like Twilio.
The OpenAI Agents SDK automatically picks the right transport. It uses WebRTC in browsers and WebSocket for server-side applications.
Building a Phone Call Agent
For phone calls, you need a telephony service like Twilio. The architecture looks like this:
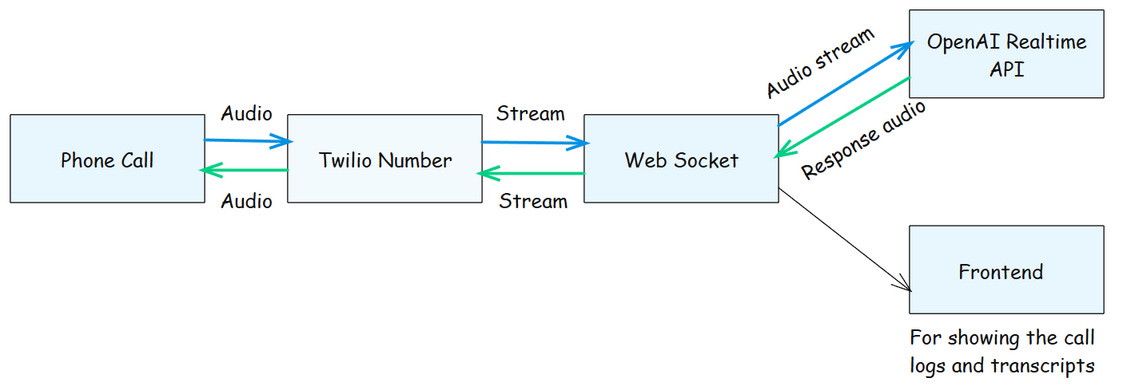
How it works:
User calls a Twilio phone number.
Twilio connects to WebSocket.
WebSocket forwards streaming audio to OpenAI.
The Realtime OpenAI API responds back in audio.
Audio streams back through the same path.
OpenAI provides a complete demo on GitHub showing how to build a phone call agent with Twilio.
4. Building Voice Agent without Code - Vapi.ai
Not everyone wants to write code. Sometimes you just need to build the agent fast. That’s where platforms like Voiceflow and Vapi comes into the picture.
Building with Vapi:
Vapi’s platform is self-explanatory. You can explore on your own. But here’s what I built as an example.
I created a voice assistant called “Abigail” that checks domain availability. You call the assistant, ask if a domain name is available, and it tells you in real-time. Simple use case to show how Vapi works.
1. Create an Assistant
I created an assistant called “Abigail” and configured the basics like model, voice, and first message.
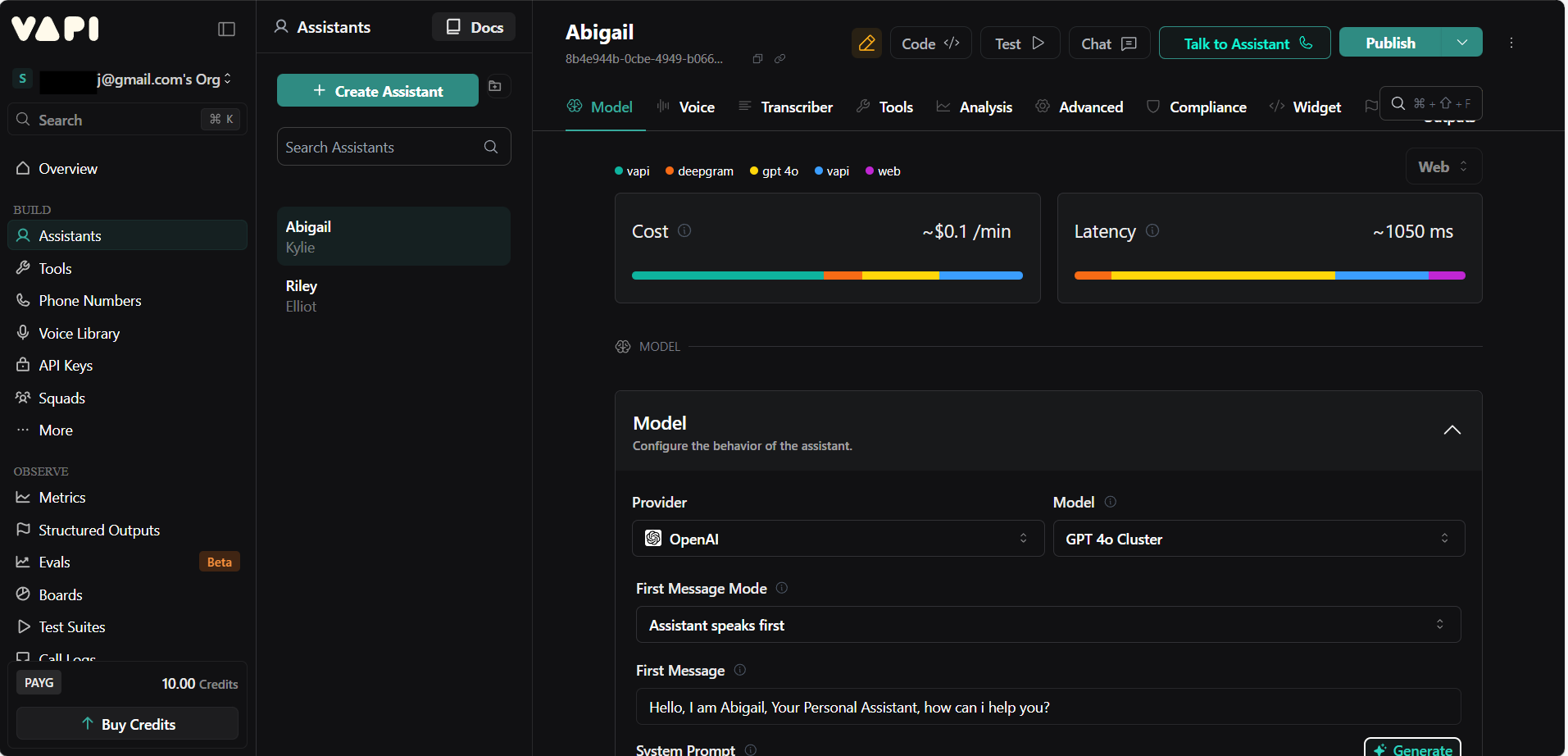
2. Add Tools
You can add available tools and integrations. Slack, Google Sheets, API calls etc.
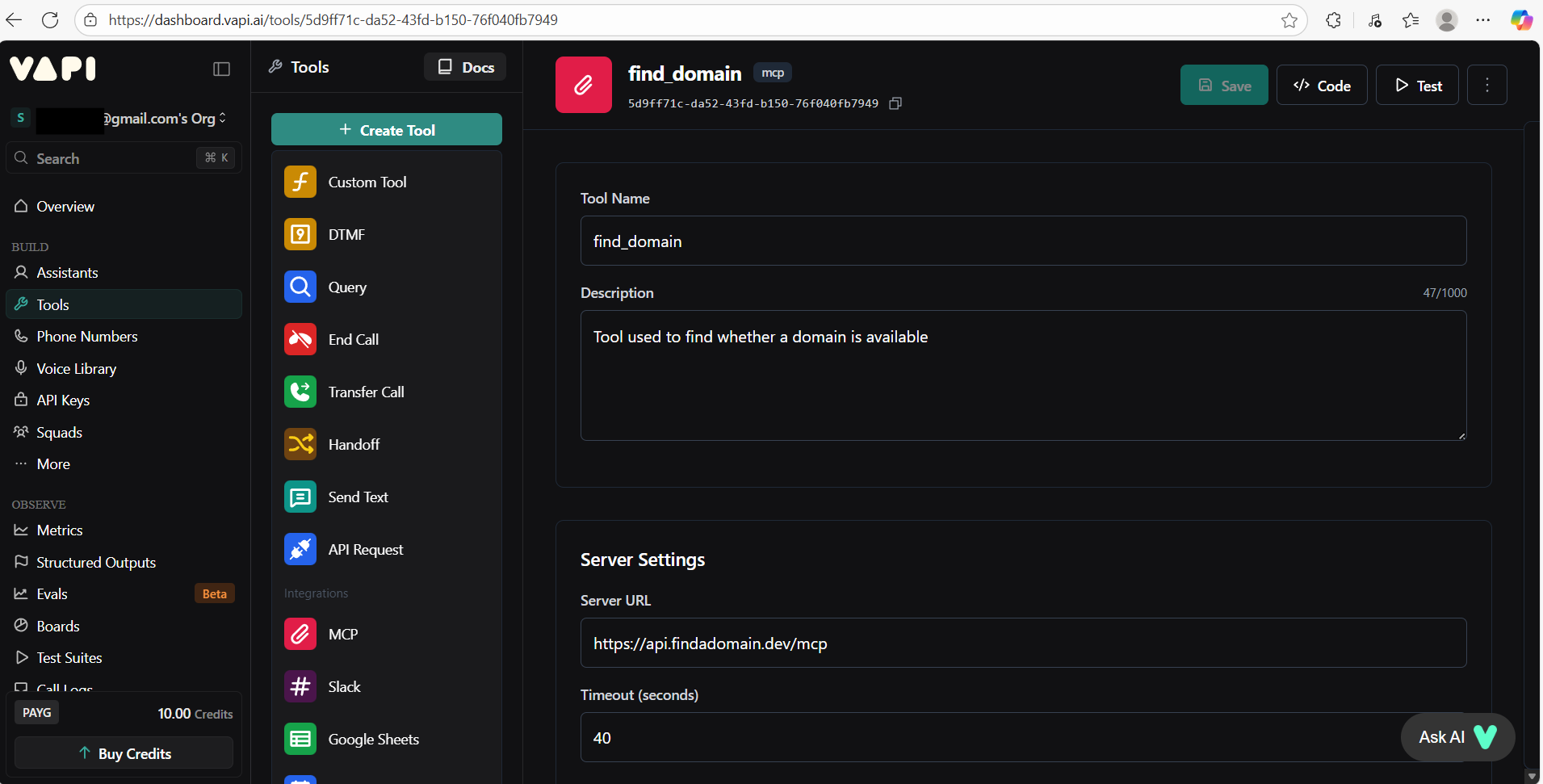
I integrated MCP Tool to check domain availability. Tools let your agent take actions during calls.
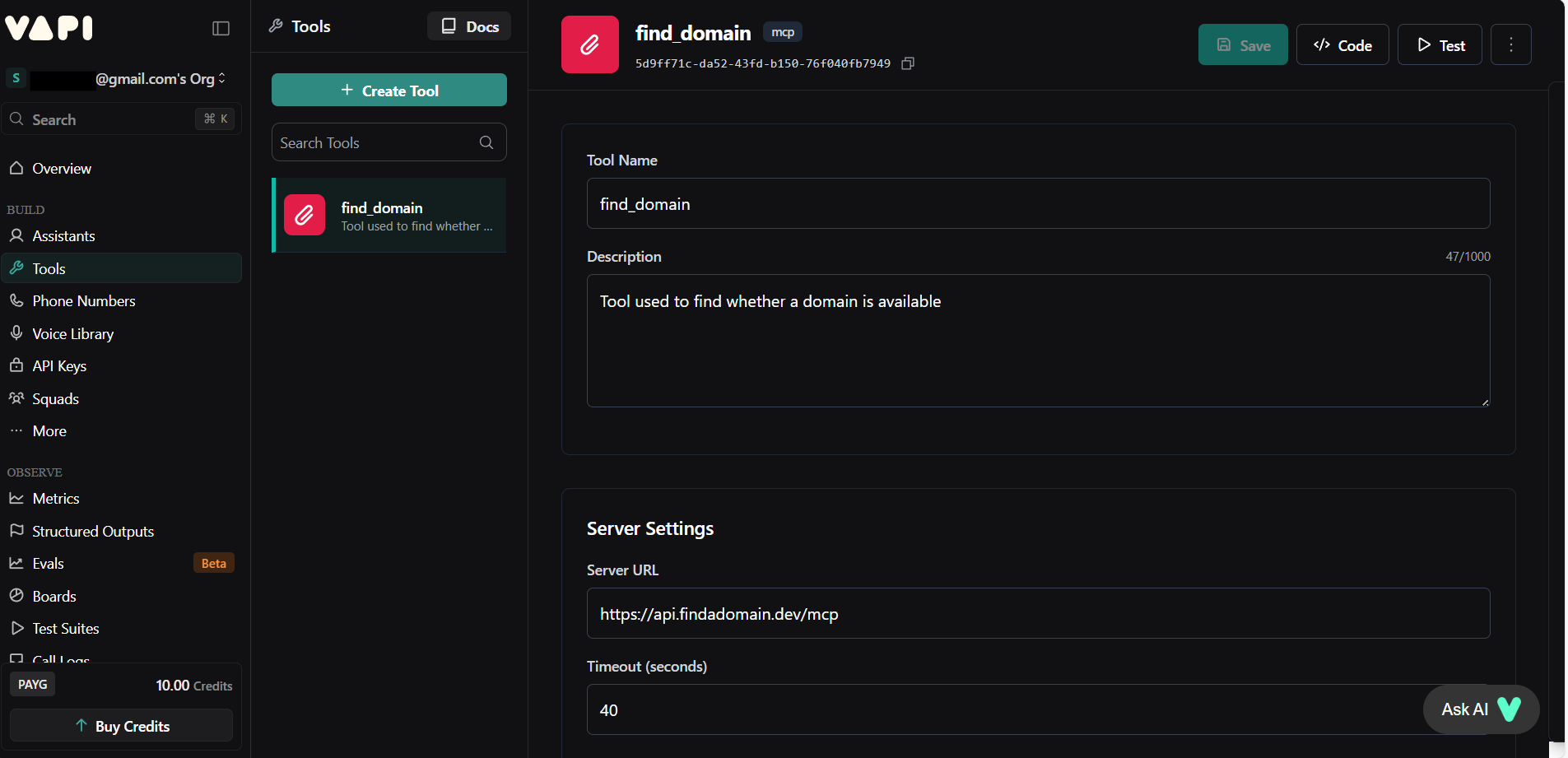
3. Configure Call Settings
Vapi supports both inbound and outbound calls. You can configure phone numbers for either direction.
Inbound - Agent receives calls. Users call a phone number, and your agent answers.
Outbound - Agent makes calls. The agent dials phone numbers to reach users.
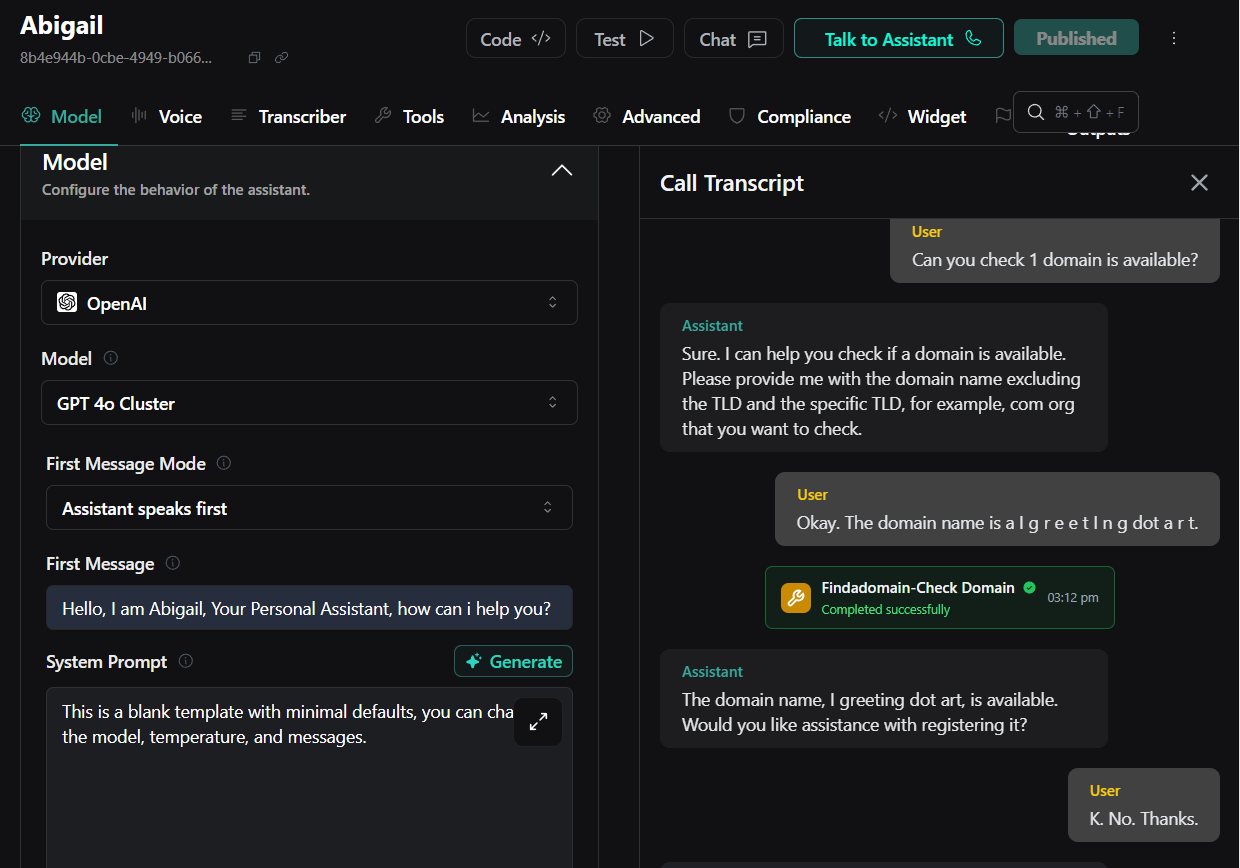
4. Test and Publish your Voice Assistant

I tested it with a call. Here’s the transcript.
You can connect Vapi with n8n agentic workflow. We’ll save that topic for next blog. If you want to see how it works now, check out this video that walks through the vapi and n8n setup.
Building with Voiceflow: FAQ Agent
Voiceflow is another no-code platform for voice agents. It’s drag, drop, and configure.
I built an FAQ agent called “Ellie” for Dr. Jones Clinic. The agent answers common questions about consultation hours, appointments, insurance, and services.
1. Create the Agent
I started with a new agent and named it “Ellie - The FAQ Agent.”
I did set up a greeting message. The Start block connects to the Agent block. That’s the basic flow.
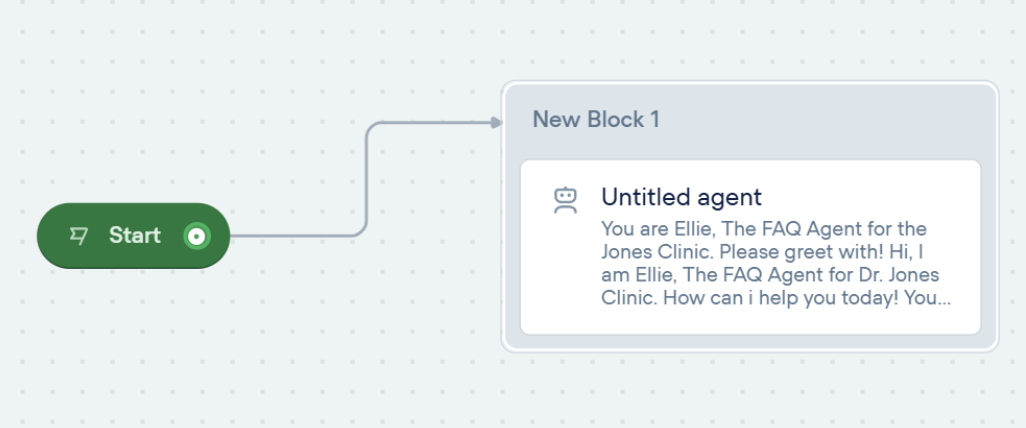
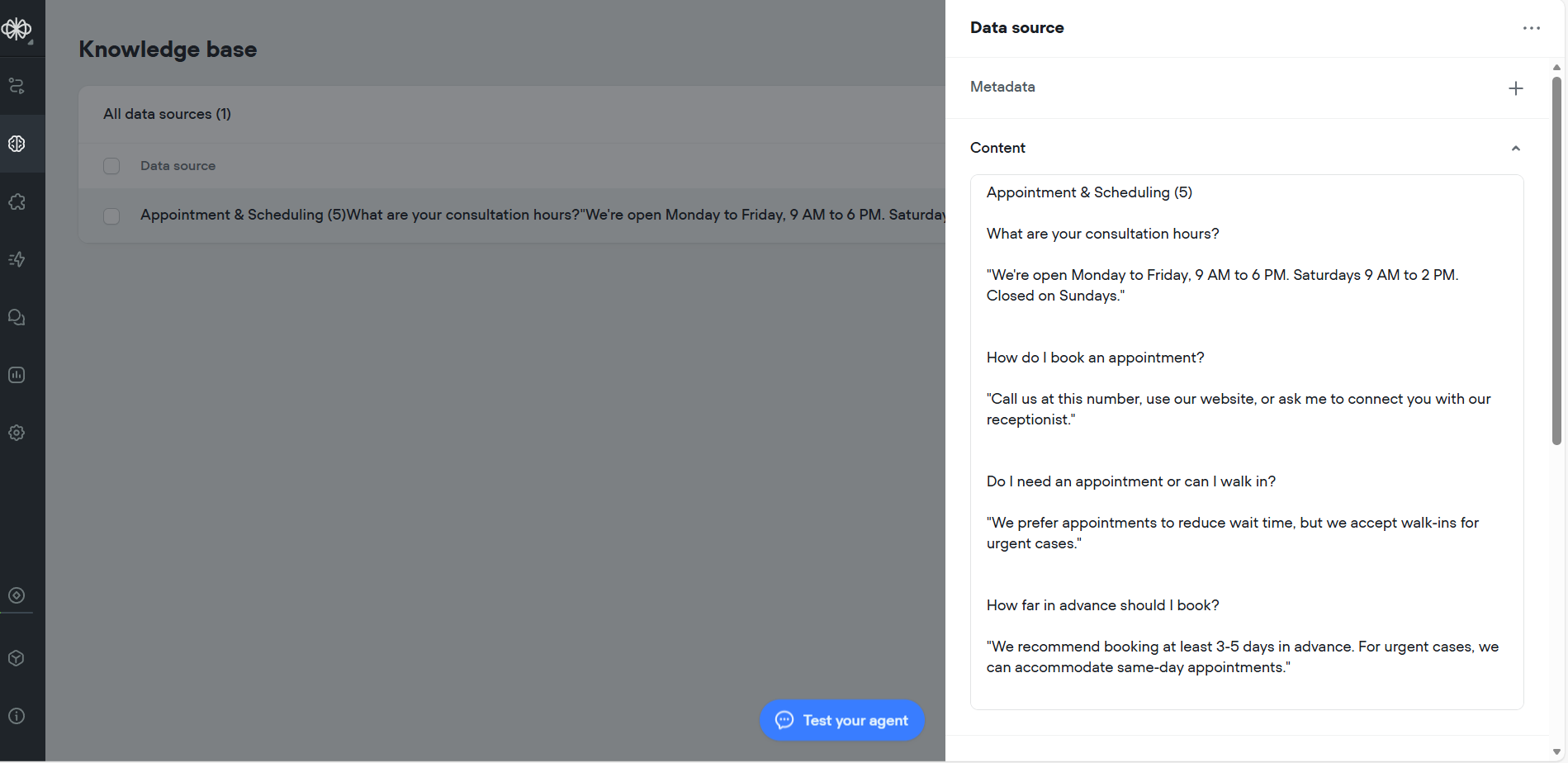
2. Add Knowledge Base
I went to the Knowledge Base section and created a data source called “Appointment & Scheduling.” Added FAQs as text content.
The “Ellie - The FAQ Agent” can now read this knowledge base and respond to user’s questions.
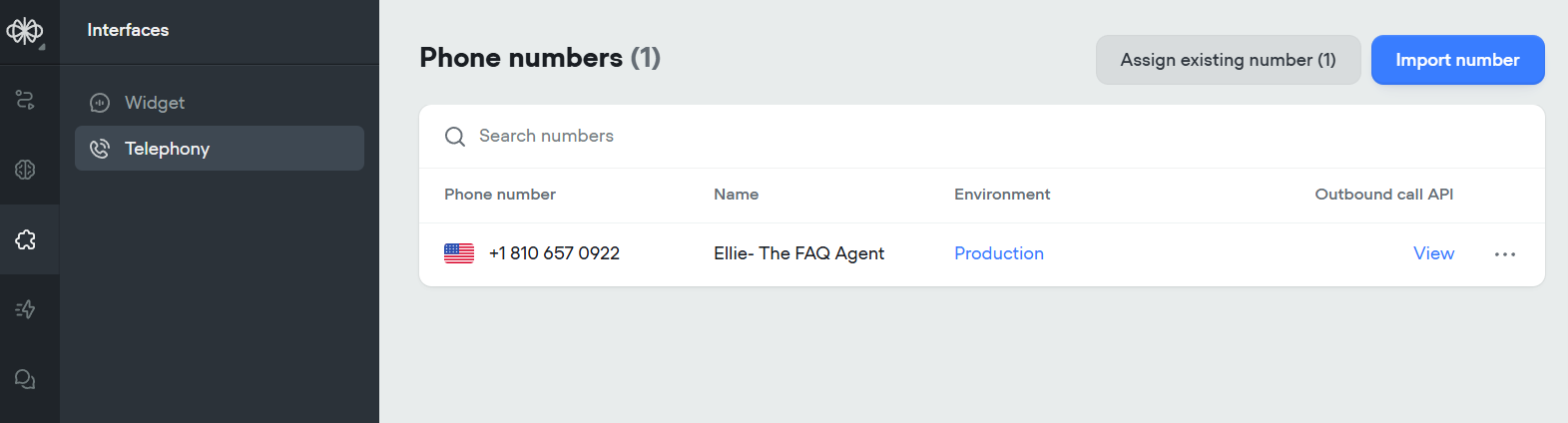
3. Connect a Phone Number
I went to Interfaces > Telephony > Phone numbers
I added a Twilio number. Now the agent can receive calls.
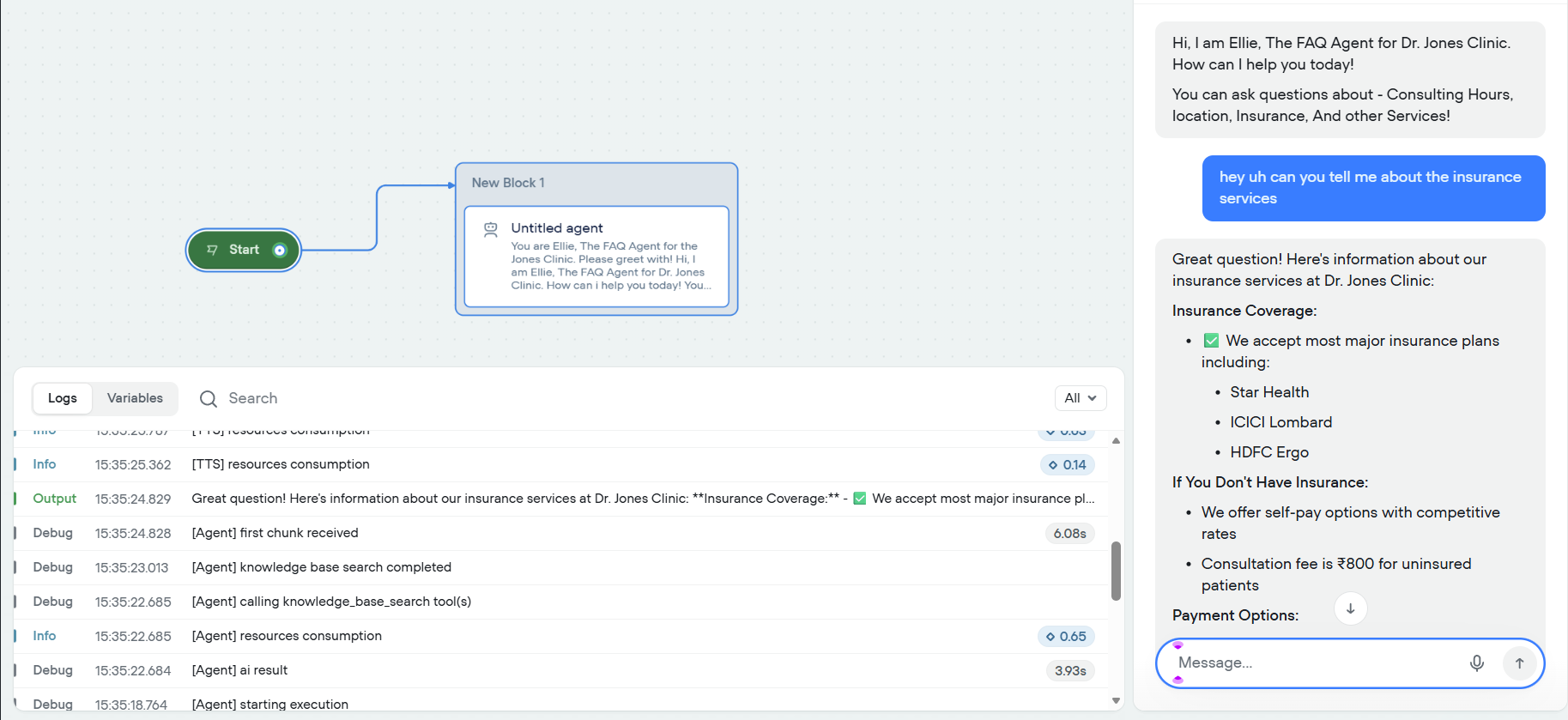
4. Test and Publish
I talked to Ellie. Asked about insurance services. She answered using the knowledge base. Here is the transcript.
Other platforms like Retell AI and Synthflow offer similar capabilities. The setup is mostly the same - configure, connect, and deploy.
Here’s a customer support agent I built in Retell AI
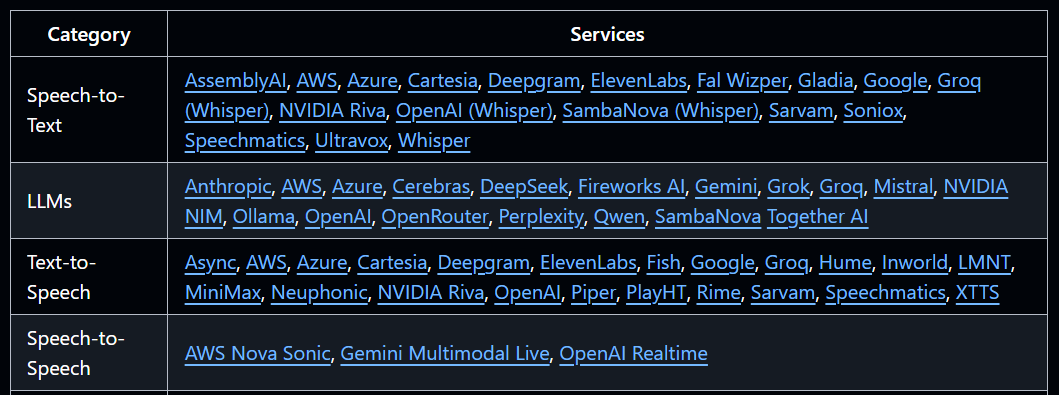
5. Further Reading: TTS, STT, and Speech-to-Speech Models and APIs
Building voice agents means choosing the right models. Here are resources to explore.
Speech-to-Speech Models:
Speech-to-Text (STT):
Text-to-Speech (TTS):
These links will help you pick the right models for your voice agent. Compare costs, latency, accuracy, and pick what works for you.
Conclusion
We covered two ways of building voice agents.
Code frameworks like OpenAI SDK,
No-code platforms like Vapi, Voiceflow
Code gives you control. No-code gives you speed. Pick what fits for you.
Start small. Build one voice agent. Test it and see what works.
Voice AI is here. The tools are ready. Now it’s your turn to build one.
Happy Building!
Excellent deep-dive into the technical side of voice agents. As this post shows, there's a lot of code and integration work involved.
For anyone reading this who wants the end-result without building the entire stack, a no-code solution is a great alternative. I'd suggest taking a look at Monobot.ai. It's designed for building sophisticated voice AI agents and handles all the complex STT/LLM/TTS integration on the backend, letting you deploy in a fraction of the time.
Couldn't agree more. Its real-time reasoning capability is just wild. What if we see this tech fully integrated into classroom learning assistants next?