
From Text to Code: A Deep Dive into How Code Generation Models (CodeQwen) Transform Prompts into Code

Code generation models transform natural language instructions into executable code. They are trained on extensive repositories of source code spanning multiple programming languages. From the simplicity of Python to the performance-focused Rust, and from the Ever-present C to the modern concurrency of Go, these models have ingested and learned from millions of lines of code and best practices in coding, common patterns, and domain-specific solutions.
AI models are now often pre-trained on code, even when not built for coding tasks, to improve their overall abilities. Newer models, like Llama 3, now incorporate a larger proportion of code data, with 17% in its pre-training mixture compared to Llama 2's 4.5% (source: Effect of code in Pretraining). AI experts believe using code data improves how well models handle various tasks requiring structured thinking.
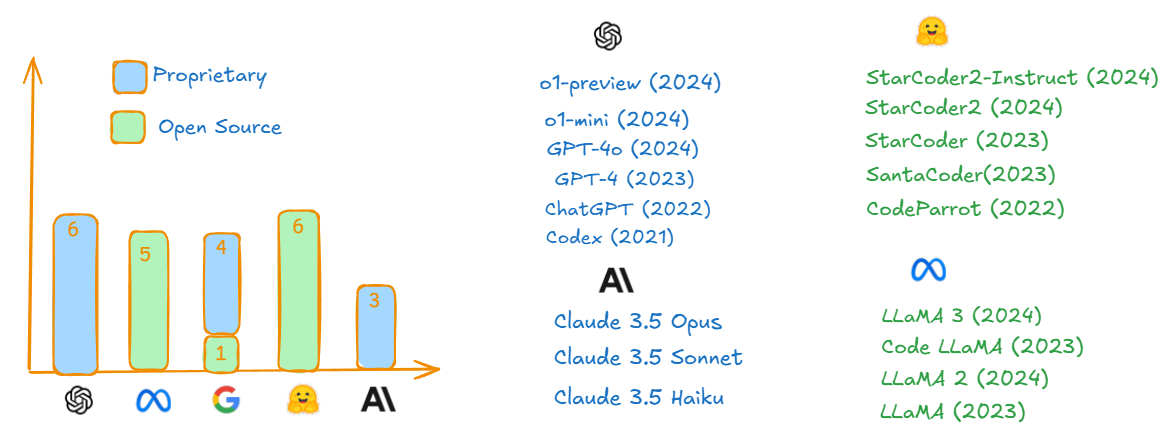
Code Models Over the Years from AI Providers
This overview presents the evolution of code models from various providers. OpenAI, Hugging Face, Meta, and Anthropic have developed models designed to assist with code generation and other tasks like code completion, code translation, etc... For the most up-to-date rankings of code generation models, visit the Hugging Face leaderboard. These models illustrate the increasing focus on enhancing coding capabilities through AI.
Source:- LLM for Code Generation
From Prompt to Code:
Today’s code generation models can produce functional code from natural language prompts. But how exactly do they accomplish this when given a prompt like "write a function to extract webpage content"?

While the diagram above illustrates the input prompt and the resulting code output, it's merely the tip of the iceberg. We will explore the mechanisms that drive these models to convert natural language into functional code.
Implementing CodeQwen: From Text Prompts to Functional Code
The below script utilizes the CodeQwen Model (With a human evaluation score of 83.5%, this 7B parameter model demonstrates strong code generation abilities comparable to human developers) to generate code from text input. Through this implementation, we explore the model's code generation pipeline, observing how it interprets our prompt and constructs the corresponding code output.
The CodeQwen Model is a decoder-only model. Explore more here to understand the distinction between encoder-decoder models and decoder-only models.
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda" # the device to load the model onto
model = AutoModelForCausalLM.from_pretrained(
"Qwen/CodeQwen1.5-7B-Chat",
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained("Qwen/CodeQwen1.5-7B-Chat")
prompt = "Write a function to find the shared elements from the given two lists."
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(device)
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
The flow of the above program is

Let's dissect the above code generation script to understand each component of the text-to-code transformation pipeline
Input Processing:
Let's break down how we structure our input for the model.
The input is a simple list of JSON messages, containing two key pieces:
A 'role': Identifies who's speaking (system or user)
A 'content': Contains the actual message
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}
]This structure enables the model to understand the source of instruction, the required task, and the appropriate context for code generation.
We then use the tokenizer to apply a chat template to our messages:
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)Learn more about the apply_chat_template() method here
The tokenizer formats our messages into a structured string, adding special tokens like <|im_start|> and <|im_end|> to mark the beginning and end of each message. By setting tokenize=False, we receive this formatted string instead of numerical token IDs.
Here's how the resulting text appears:
<|im_start|>system\nYou are a helpful assistant.<|im_end|>\n<|im_start|>user\nWrite a function to find the shared elements from the given two lists.<|im_end|>\n<|im_start|>assistant\nNext, we transform the formatted text into a format our model can process. The tokenizer converts the text into a sequence of numbers (token IDs) and then organizes these into tensor structures. These tensors serve as the direct input for our code generation model.
model_inputs = tokenizer([text], return_tensors="pt").to(device)The model_inputs, now in tensor format, appear as follows:
{
'input_ids': tensor([[3, 10326, 1396, 4260, 1789, 1643, 7741, 13710, 35342, 4,1396, 3, 5435, 1396, 11490, 1643, 2572, 1676, 2451, 1651,6731, 5555, 1829, 1651, 3041, 2164, 12350, 35342, 4, 1396, 3, 1864, 15504, 1396]], device='cuda:0'),
'token_type_ids': tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]], device='cuda:0'),
'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]], device='cuda:0')
}Output (Token ID) Sequence Generation:
After processing and tokenizing our input, we move to the core of code generation. The model now takes center stage and generates output token IDs for the respective input token IDs using the below step. When the model processes these input tokens, it uses its attention mechanisms to understand the context and requirements of the task. The model doesn't simply find something relevant but rather builds a contextual understanding of what's being asked.
generated_ids = model.generate(model_inputs.input_ids,max_new_tokens=512)The model generates code, one token at a time, using its trained knowledge and self-attention with causal masking. Each token's probability is calculated as P(next_token|previous_tokens) = softmax(logits/temperature) ensuring the code stays contextually and syntactically accurate.
The output generated_ids appears as a tensor of numerical IDs like below.
[tensor([18528, 1709, 1748, 3415, 2572, 1672, 18773, 1726, 10292, 1651,
6731, 5555, 1829, 1651, 3041, 2164, 12350, 35371, 30, 18414,
35425, 18589, ....... 2607, 12350, 1679, 2358, 1643, 2769, 1677,
5555, 1726, 5437, 1785, 3373, 3576, 1672, 2607, 12350, 35342,
4], device='cuda:0')]Token to Text Decoding:
Finally, we convert these numerical tokens (output token IDs) back into human-readable code.
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]Below is the output generated by our script a Python function created in response to our prompt.
Here is an example function in Python that finds the shared elements from the given two lists:
```python
def shared_elements(list1, list2):
shared = []
for i in list1:
if i in list2:
shared.append(i)
return shared
```
You can call this function by passing in your two lists as arguments, like this:
```python
list1 = [1, 2, 3, 4, 5]
list2 = [4, 5, 6, 7, 8]
print(shared_elements(list1, list2)) # Output: [4, 5]
```We've walked through the process of how a code generation model works, from input to output. However, the inner workings of these models involve deep mechanisms that enable them to understand context, generate coherent code, and apply learned patterns.
Speaking of advancements in this field, Qwen's newest release, Qwen2.5-Coder-32B-Instruct, has set new benchmarks in code generation, surpassing many established models in the field. Check the discussion here.
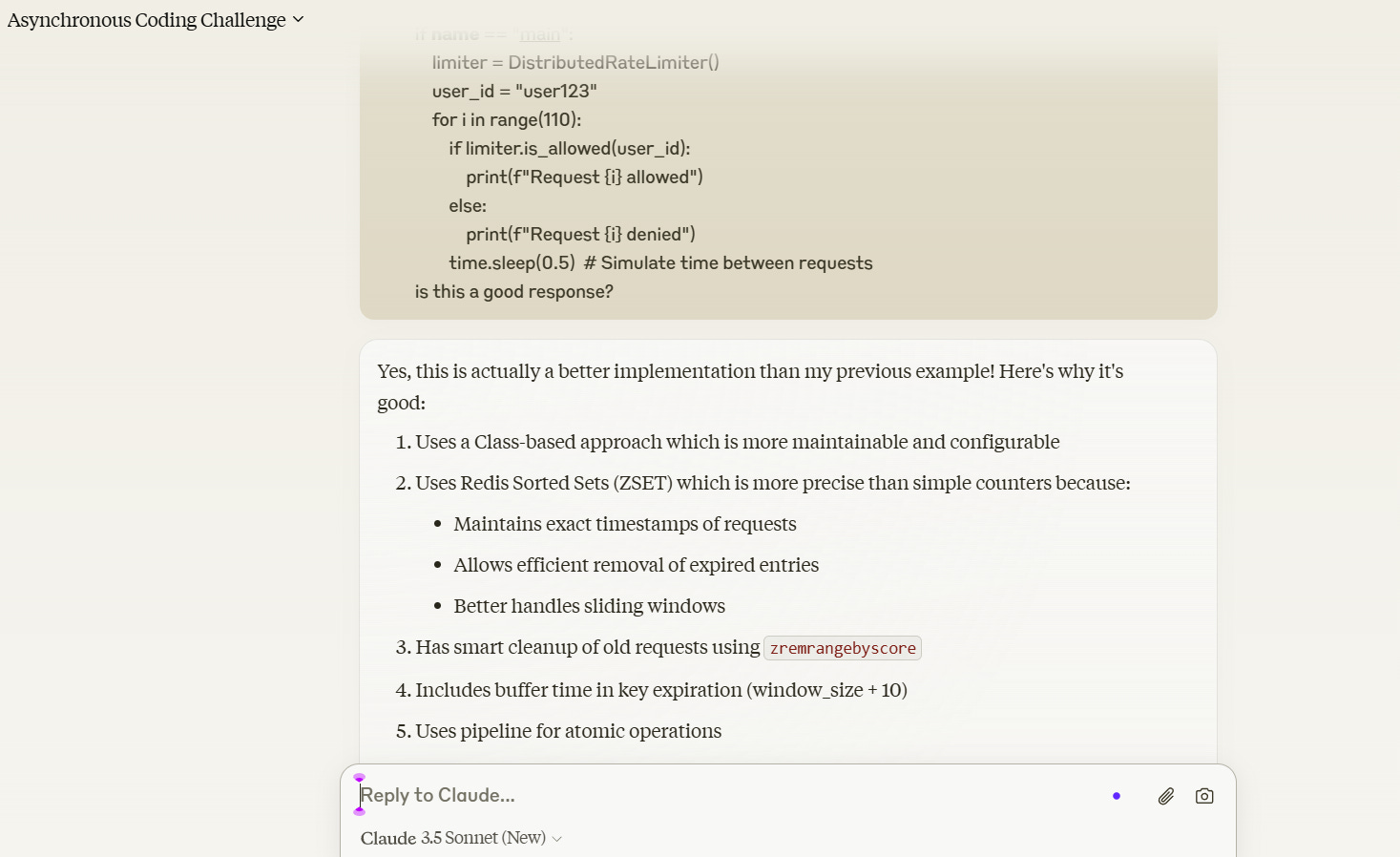
Claude and Qwen2.5 Coder- The Unexpected Cherry on Top
In an interesting experiment, I posed the same coding challenge to two different AI models - Claude 3.5 Sonnet and Qwen2.5-Coder-32B-Instruct. The task was to implement a distributed rate limiter using Redis. While Claude provided a functional solution using simple Redis counters and time-based bucketing, CodeQwen's response impressed with its production-ready approach using Redis sorted sets (ZSET) for precise request tracking and automatic cleanup. What's fascinating is that Claude acknowledged the quality of CodeQwen's implementation, highlighting how AI models can not only generate different approaches to the same problem but also evaluate and appreciate each other's code quality, much like human developers reviewing each other's work.
Get to Know More:
Our exploration of code generation, particularly with the Qwen model, shows how these models handle real-world programming tasks. For those interested in the technical foundations, the paper on LLMs for Code Generation provides a comprehensive deep dive into the architectural innovations and mechanisms that power these capabilities.
Check out the paper for detailed insights on
Multi-Head Self-Attention (MHSA)
Masked -Attention
Position-wise Feed-Forward Networks (PFFN),
Token-by-Token Generation etc.…
Hope you’ve gained insights into how code models operate!
We'll continue exploring advanced concepts in AI and Large Language Models in subsequent technical discussions.
Happy learning!