
Data-centric AI - a new ML pedagogy
Issue #27

Hello 👋🏽
Welcome to the 27th edition of DevShorts!
I write about developer stories and open source, partly from my work and experience interacting with people all over the globe.
Some popular issues from DevShorts:
Join 1000+ developers to hear stories from Open source and technology.
Artificial Intelligence Ecosystem
I don’t need to guess this one, as everyone knows what AI is (or thinks they know…). But, today, AI is one of the most discussed trends in a University or Board Room.
The impact of AI on non-software applications is enormous. However, the AI community faces many fundamental problems, from training the models to getting the right talent at various levels and deploying models in production.
Among them, data quality is an under-discussed area, apart from data collection, data bias, and storage which are also essential data-related issues.
The Data Quality Problem
We mostly talk about data ingestion, data storage, data lake architecture, and model bias., but not much about the quality of data itself!
Speaking from a data engineer’s perspective, they spend a reasonable amount of time troubleshooting the data. It is the first question that comes to the mind of a data engineer when the problem is to be solved.
Once, I got an opportunity to talk to a senior engineering lead who runs an ML team at a Fortune 100 company. The team’s work is pivotal to the organization’s future products. But the quality of data they receive to train the models is just “ok”.
We spoke at length about what tools enable engineers to do the grunt work of labelling the data. Unfortunately, we did not see great alternatives that enable engineers to do this work easily.
Besides, due to the nature of problems solved by the ML team, the data size, shape, and format vary. For example, it could be images, text, or audio clips, which further complicates the problem.
How will Data Quality help organizations?
A quality dataset with the right set of labelled training data leads to an efficient model, which could predict better outcomes. Better outcomes yield a better customer experience. Better customer experience produces good brand value, better revenue etc.
You see, data quality is directly linked to organizations’ revenue :D

I read a few papers and learned about a few companies doing phenomenal work in this area, which I will discuss in the coming section.
Data-centric AI
Data-centric AI (DCAI), as described by Dr. Andrew Ng, one of the pioneers of machine learning (ML), “is the discipline of systematically engineering the data used to build an AI system.”
Data-centric AI tries to put data in the center of ML model development.
And, there are few developer companies apart from Google, AWS solving it.
Cleanlab is an open source library; getting bootstrapped as a company, looks exciting to me. The project aims to fix the dataset quality issue. They have a no-code tool (which I haven’t tried yet!) in the works to make it easier.
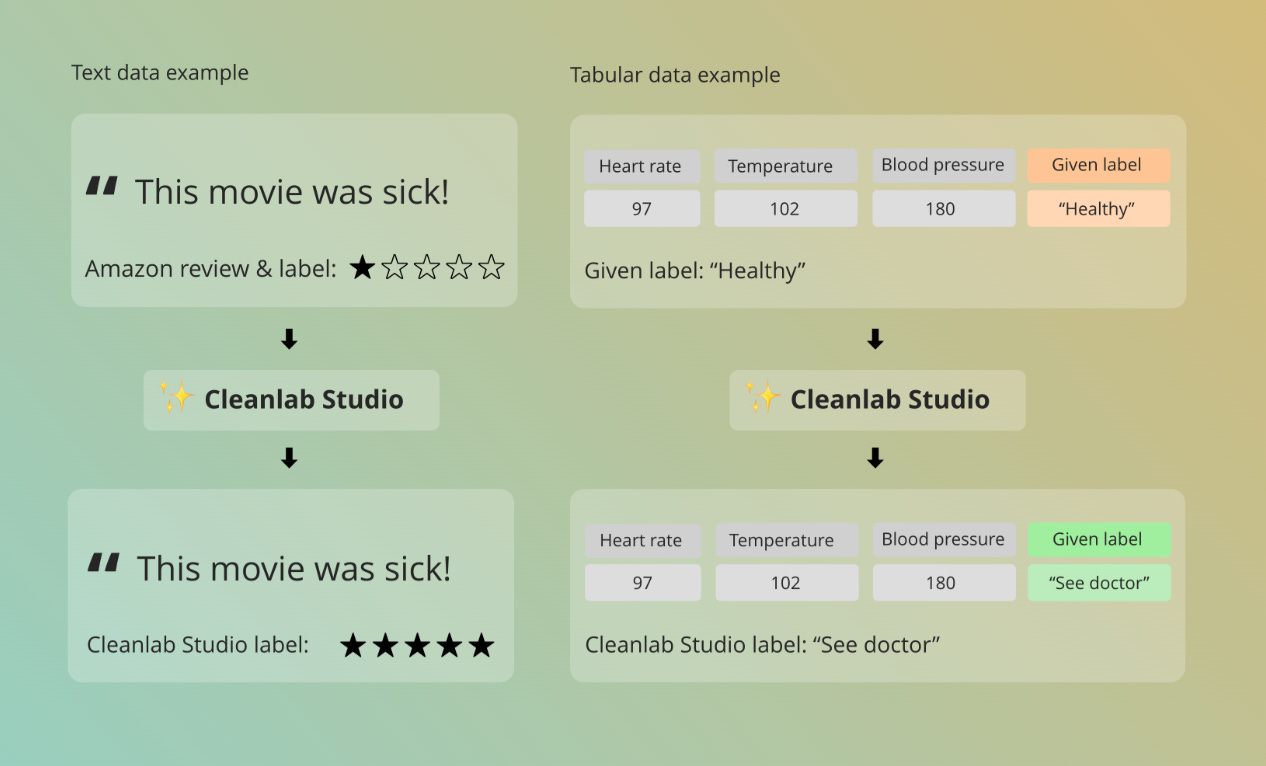
They have a fascinating site to point out the labelerrors from popular datasets.
Kern.ai and Diffgram are a few others trying to address this by setting up an IDE-like environment.
Dataperf, a benchmarking suite to evaluate the quality of training and test data, and the algorithms for constructing or optimising such datasets.
Overall, I feel this is a much-needed area of research for data team(s) productivity. The academic and organizational efforts are taking shape - Dataperf, a benchmarking suite to evaluate the quality of training and test data, and the algorithms for constructing or optimizing such datasets.
Further Reading
Confident Learning: Estimating Uncertainty in Dataset Labels
Data collection and Quality challenges in Deep Learning: A DCAI perspective
Interesting Blogs
Managing Kubernetes Secrets with External Secrets Operator - I’m seeing more content around k8s’s external secret managers nowadays.
How to Build Great Open-Source DevTools: With Max Howell (Creator of Homebrew)
PlanetScale CEO on Cloud-Prem and Climbing the Engineering Ladder
Opensource Project
Apache DevLake is an open-source dev data platform that ingests, analyzes, and visualizes the fragmented data from DevOps tools to distill insights for engineering productivity.
DevLake could be a great value add for Program Managers in the Engineering Productivity area. It only has a couple of integrations now and incubating in ASF. But can make an impact on engineering teams as an OSS project in future.

If you’re finding this newsletter valuable, consider sharing it with friends or subscribing if you haven’t already.
Aravind Putrevu 👋🏽