
Automating the life of a DevOps Engineer
Issue #28

Hello 👋🏽
Welcome to the 28th edition of DevShorts!
I write about developer stories and open source, partly from my work and experience interacting with people all over the globe.
Some popular issues from DevShorts:
Join 1000+ developers to hear stories from Open source and technology.
It has been a while since I have written on DevShorts. The last six months have been quite a journey for me, personally and professionally. First, I moved to a different country with my family. Second, I quit my full-time job. More on that may be in my blog.
But, in this issue, I would like to bring your attention to an important product category being built. It is not a Heroku alternative, a managed k8s-as-a-service, or a Serverless DB. Instead, it is a script automation platform!
As much as I put it out bluntly, it has more valuable features being built out, and the area is burgeoning with many startups (dev tools).
The Story
After a long time, Sejal meets her friends at their usual hangout place in Bengaluru after office hours.
She is excited because she gets to meet everyone after a long gap due to the pandemic. She works as a Senior DevOps Architect at a prominent e-Commerce company and leads quite a few service & infrastructure reliability initiatives.
As Sejal has chosen her main course, her phone starts to ring. Her colleague requested her to help as the “Runbook” she wrote wasn’t working and disrupted the search service. She is not the primary on-call person for the week but a secondary person to help with any significant service disruption.
It is a Friday evening with a few hours to the big-bang selling campaign.
The management will not be able to afford an effective service like Search on the website to be unavailable.
Thanks to remote work, She opened slack on her laptop to find the crux of the issue. Quickly executed the necessary command. The service is back UP!
The team is relieved and tasked to monitor the service for a few hours. Then, on the next working day, she has to prepare a post-mortem report on what went wrong.
She returned to the party thinking about what could have gone wrong, as her task was to plan for risk mitigation in the infrastructure processes. She has built processes like building a Runbook knowledge base to help the team solve issues without dependency. Her team continuously shares, updates the knowledge base, and even tries to automate a few use cases via Observability and ChatOps tools.
The next day, she found that the Runbook had missed an essential step in configuring the environment. As a result, it has led to a significant service disruption, even though the entire exigency is planned.
BTW, What is a Runbook?
Infrastructure & Operations teams usually store the most common debugging workflows in scripts or API. These scripts help the on-call ops team to survive during an incident.
Most commonly, the parameters to run the script and the potential results to check are often coded in a step-like fashion in a wiki article on a tool of the team’s choice (Confluence, Github Repo, etc.)
During an incident, the Ops team can pick up the Runbook, run scripts with the parameters mentioned, and analyze the results to rectify an issue.
For example, a runbook with a list of commands for disk cleanup or a runbook to restart the application with suitable parameters.
The word Runbooks are not so common, but each team stores this “tribal knowledge” that people experience over the years in their product using tools like Bugzilla or even a simple word doc.
Why Runbooks?
There are multiple reasons Runbooks exists:-
Collating the common/trivial solutions to issues in the environment. (If/Until the engg team acts on them!)
Creating a knowledge base for future team members.
Not “Re-invent the wheel” - especially when the fire erupts.
Automating the “Tribal Knowledge”
Nevertheless, and as good as it sounds, Runbooks could potentially create problems if not maintained.
As discussed earlier, Runbooks are executed by teams for pro-active or reactive use cases such as rotating credentials, identifying users/servers with specific permissions, restarting a Kubernetes service, JVM heap dumps, etc.
Notice that each system is tied to a version or a flavor of that system. The commands and APIs written in a Runbook might not work in the long run or needs to be updated retroactively. There is a good chance of mishap if wrong commands or APIs are executed on production environments.
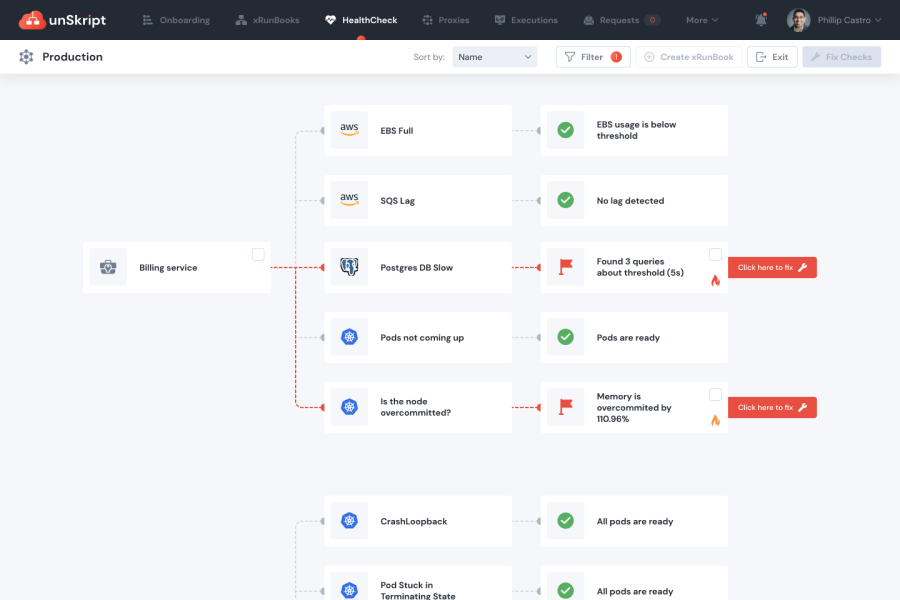
Runbooks are good knowledge repositories, but potential hazards exist with too many teams or users with varied permissions and system complexities.
Here is where companies like Unskript, Fiberplane, and Blinkops are attempting to solve this problem for the DevOps and SRE communities. They were separating the systems, credentials, and users into individual actionable components (like blocks) for repeated execution. Thereby using the same actionable block in multiple Runbooks, creating a chance for the team to collaborate on Runbook.
Once automated, these platforms could become a feed to discuss and prepare an auto-generated post-mortem.
Interesting Blogs
A Software developer’s guide to Technical writing - Ankur has written an essential blog for all of us to read :)
What is Kubernetes? - Well, it is never wrong to learn again!
Guidelines to Get a Data Engineer Job Against the Odds - From a great community with excellent points to learn from.
Docker Best Practices - A good gist!
Opensource Project
Pynecone is a full-stack framework for building and deploying web apps. Its USP does not need much JS integration (uses Node) and built-in UI components. You can take a look at existing apps here.

If you’re finding this newsletter valuable, consider sharing it with friends or subscribing if you haven’t already.
Aravind Putrevu 👋🏽